AWS EKS Pod 出現 aws-cni failed to assign an IP address to container 錯誤
此文章是我在公司擔任架構師,在負責稽核資源使用時,有發現有同仁的 AWS EKS node_group 資源開太大 (開發環境使用 2xlarge 機器規格),所以先手動從 UI 去調整 Node 的機器規格 (RD 未提供建立時的 Terraform 版控),從 m7g.2xlarge 先改成 m7g.large。
但由於同仁是用 Terraform 來建置整座 EKS + node_group,有 Launch Templates 以及 Auto Scaling Groups 等元件,能調整機器規格的只能從 Launch Templates 以及 Auto Scaling Groups,但 Launch Templates 沒辦法編輯 (只能新增、刪除),當時為了想要先快速的減少花費,因此先直接調整 Auto Scaling Groups 的 Node 機器規格。
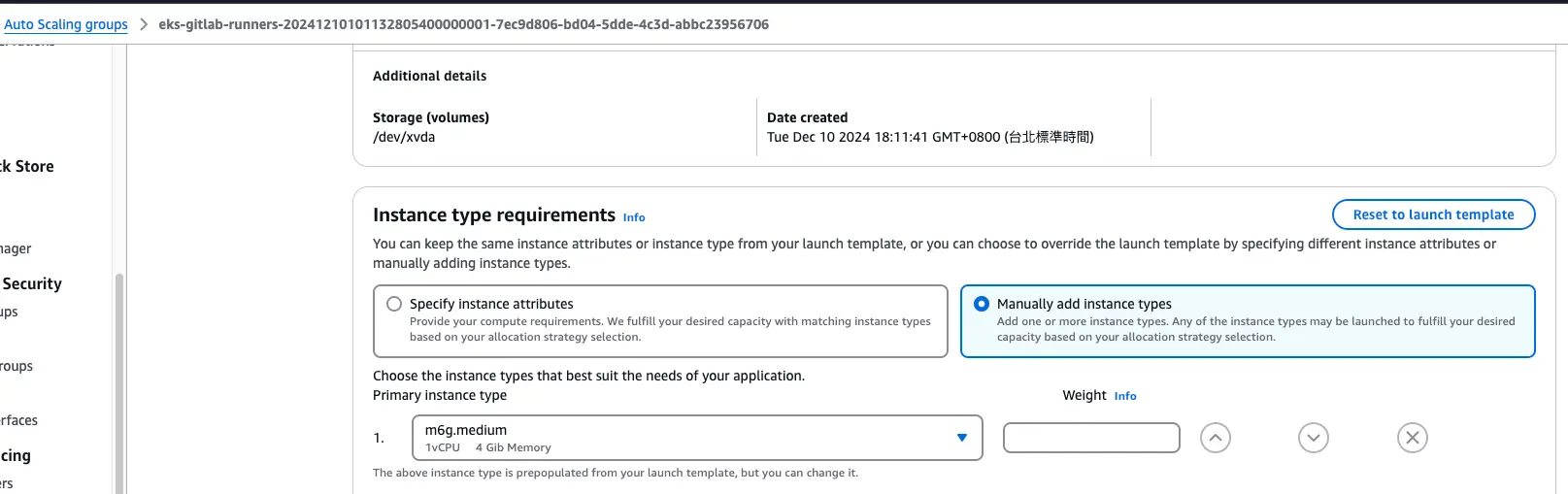
遇到問題
調整完後,再使用 Auto Scaling Groups 的 instance refresh 去更新機器規格,這時候會發現,新 Node 上的 Pod 會偶發出現以下錯誤訊息:
Failed to create pod sandbox: rpc error: code = Unknown desc = failed to setup network for sandbox "XXXXXXXXX": plugin type="aws-cni" name="aws-cni" failed (add): add cmd: failed to assign an IP address to container尋找問題
排除 Subnet IP 用完的情況
一開始看錯誤訊息 aws-cni failed to assign an IP address to container 以為是 subnet 的 IP 已經被 Pod 用完了,所以先使用以下指令來查看 Subnet 的可用 IP 數量:
aws ec2 describe-subnets \
--query "Subnets[*].{SubnetId:SubnetId, AvailableIps:AvailableIpAddressCount, CidrBlock:CidrBlock}" \
--output table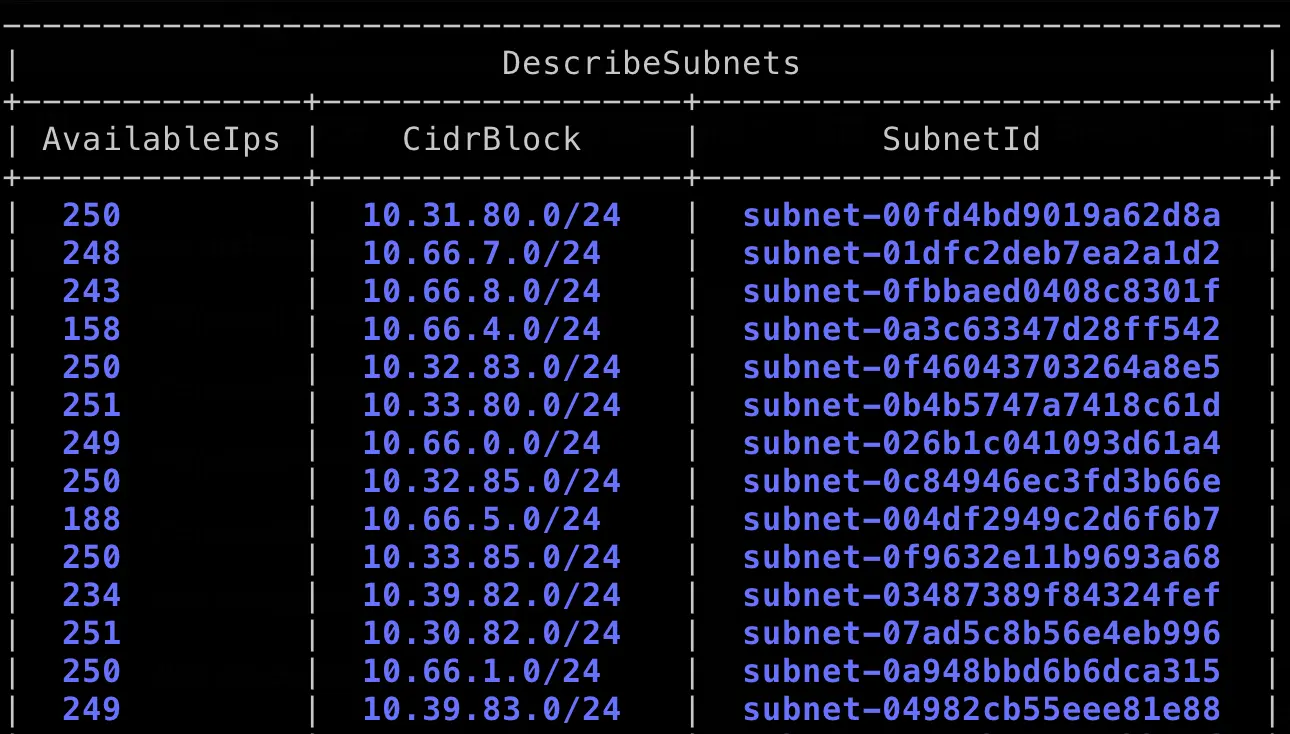
也可以從 UI 去看每一個 Subnet 的可用 IP 是多少:

AWS Subnet 計算方式:
假設是 /24 計算是: 32-24=8,2 的 8 次方 = 256
AWS 會保留 5 個 IP,如下:
XX.XX.XX.0:網路位置
XX.XX.XX.1:VPC 路由器位址
XX.XX.XX.2:Amazon DNS 位址
XX.XX.XX.3:保留給未來用途
XX.XX.XX.255:廣播位址
所以最多可用的 IP 數量是 256-5=251
排除 Pod 數量超過 Node 的限制
排除了 Subnet 用完的情況,後來搜尋了一下文件,發現 AWS 的機器規格,會限制一個 Node 上面,最多能長有幾個 Pod,這個跟 Amazon VPC CNI 插件有關,下面附上一些相關的問題連結:
那要怎麼計算什麼機器規格,Pod 的最大限制是多少,可以用這個公式來計算
ENI * (# of IPv4 per ENI - 1) + 2可以先用這個指令來看 ENI 以及 IPv4 per ENI 各是多少:
aws ec2 describe-instance-types \
--filters "Name=instance-type,Values=c5.*" \
--query "InstanceTypes[].{ \
Type: InstanceType, \
MaxENI: NetworkInfo.MaximumNetworkInterfaces, \
IPv4addr: NetworkInfo.Ipv4AddressesPerInterface}" \
--output tableMaximum IP addresses per network interface
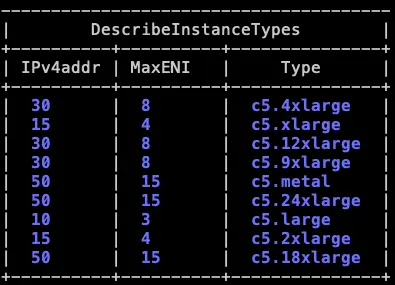
已 c5.4xlarge 來說,就是 8*(30-1)+2 = 234,一個 Node 最多 234 個 Pod,c5.xlarge 來說,就是 4*(15-1)+2 = 58,一個 Node 最多 58 個 Pod。
但如果每次都要自己計算,會有點麻煩,所以這邊再提供幾個方式:
- 官方已經計算好的對應表:https://github.com/awslabs/amazon-eks-ami/blob/main/templates/shared/runtime/eni-max-pods.txt
- 每個 Amazon EC2 執行個體類型建議的最大 Pod 數腳本:Amazon EKS recommended maximum Pods for each Amazon EC2 instance type (但這個計算最高只會顯示 110,詳細可以看文件)

但是,如果是超過 Node 的 Pod 最高限制,應該也會是顯示以下的無法調度錯誤,而不是 aws-cni failed to assign an IP address to container 錯誤:
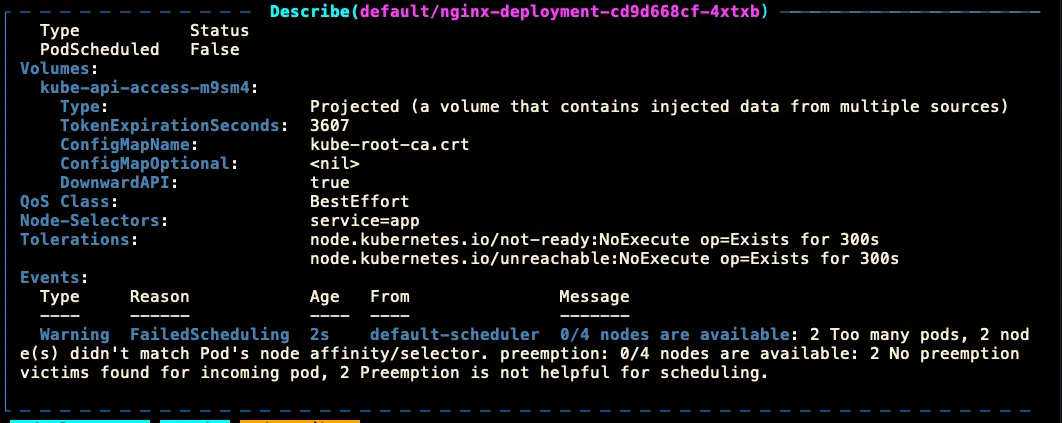
找到問題
最後發現,因為我們最一開始只調整了 Auto Scaling Groups 的機器規格,調整完後,資源的確是降低了(從 8 vCPUs / 32.0 GiB → 2 vCPUs / 8.0 GiB),但 Node 的 Allocatable pod 卻還是原本的數量限制,原因是 Controller plane 不知道我們有調整 (Auto Scaling Groups 只會調整 node_group)。
因此,當服務開上去,Node 能長的 Pod 上限還是舊的 m7g.2xlarge 58 個,但對於 aws-node 來說,cni 最多只能 m7g.large 29 個,所以超過 29 的都會出現這個錯誤,把它趕到其他 Node (還沒有滿 29 上限) 就正常。
- 可以用這個指令看到目前 Node 的 HOSTNAME、instance-type、allocatable.pods:
kubectl get nodes -o custom-columns="HOSTNAME:.metadata.name,INSTANCE-TYPE:.metadata.labels.node\\.kubernetes\\.io/instance-type,ALLOCATABLE-PODS:.status.allocatable.pods"- 有問題的 Node
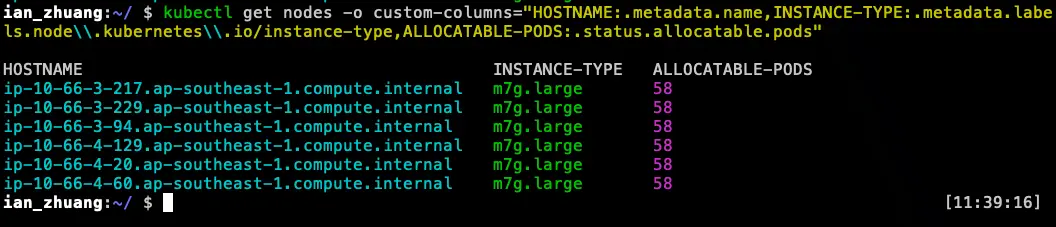
- 正常的 Node

解決問題
所以我們要避免這個問題有兩個解法:
- 更換機器規格需要重建 Launch Templates,用先建後拆,不能只更新 Auto Scaling Groups。
- 用 Terraform 做完整的管理。
參考資料
Maximum IP addresses per network interface:https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/AvailableIpPerENI.html