GCP Prometheus Samples Ingested 計算方式及如何減少費用
最近在優化公司帳單費用,發現公司有幾個 project 裡面的 Prometheus Samples Ingested 費用很高,此文章會針對費用如何計算以及如何去減少費用來做說明。
Prometheus Samples Ingested 就是 Prometheus 攝取的樣本數,因為上述幾個專案,我們都是使用 Google Managed Prometheus (GMP) 的方式來接 Metrics,所以可以先推測是 Metrics 導致此費用增加。

費用計算說明
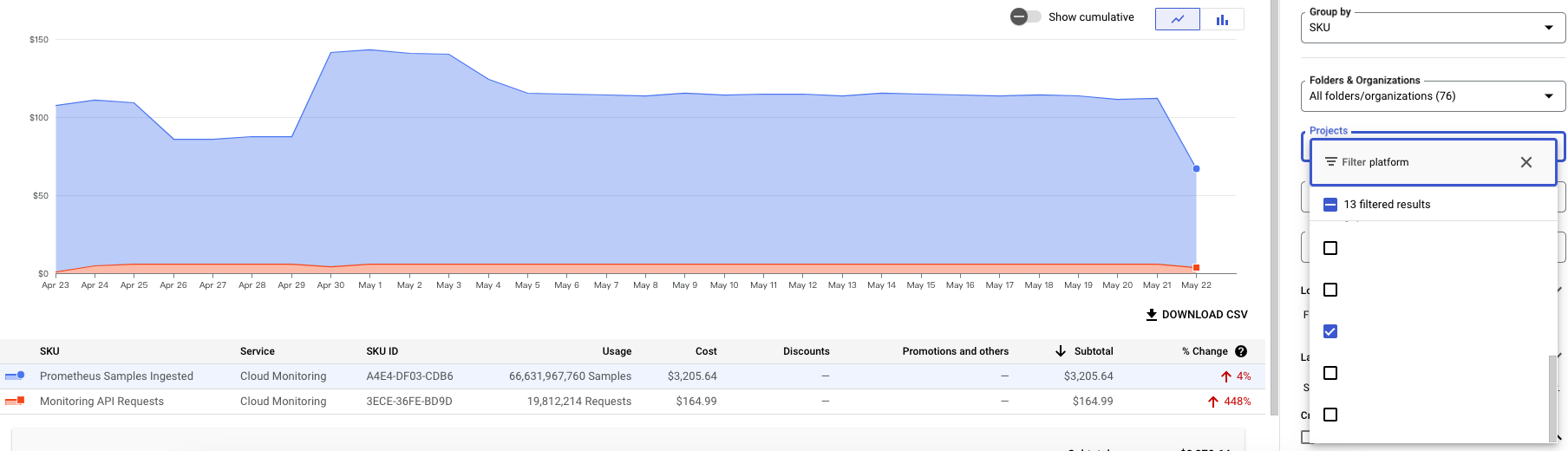
首先我們先來計算一下費用是不是正確,Prometheus Samples Ingested 的 SKU 是 A4E4-DF03-CDB6,可以透過這個頁面來查詢:

我們可以看到如果是 0 ~ 50,000,000,000 的 Samples,會以每 1,000,000/0.06 USD 來計算,其他以此類推,為了更方便的計算,我有簡單寫一個腳本來計算費用:
- calc_metrics.sh
#! /bin/bash
if [[ $# -ne 1 ]]; then
echo "請使用: $0 <samples> 來計算費用"
exit 1
fi
if [[ $1 =~ [a-zA-Z] ]]; then
number=$(echo "$1" | sed -E 's/([0-9]+(\.[0-9]+)?)\s*[a-zA-Z]+/\1/')
unit=$(echo "$1" | sed -E 's/[0-9]+(\.[0-9]+)?\s*([a-zA-Z]+)/\2/')
case $unit in
K)
factor=1000
;;
M)
factor=1000000
;;
B)
factor=1000000000
;;
*)
echo "未知單位: $unit"
exit 1
;;
esac
result=$(printf "%'d" $(printf "%.0f" $(echo "$number * $factor" | bc)))
else
result=$1
fi
echo "Samples:${result}"
result=$(echo "${result}" | tr -d ',')
if [[ ${result} -le 50000000000 ]]; then
cost=$(echo "scale=2; ${result} * 0.06 / 1000000" | bc)
elif [[ ${result} -le 250000000000 ]]; then
cost=$(echo "scale=2; ${result} * 0.048 / 1000000" | bc)
elif [[ ${result} -le 500000000000 ]]; then
cost=$(echo "scale=2; ${result} * 0.036 / 1000000" | bc)
else
cost=$(echo "scale=2; ${result} * 0.024 / 1000000" | bc)
fi
echo "費用:$cost USD"我們分別帶入 project_1 (106,676,274,756) 以及 project_2 (66,631,967,760) 的 Samples 來計算看看金額是否正確。
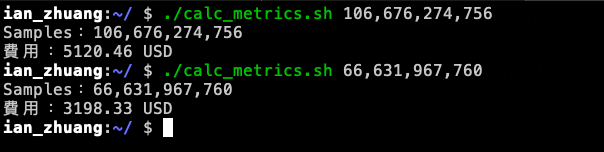
計算完與實際的帳單費用差不多,接著我們可以打開 GCP 的 Metrics Management 來查看一下,我們用了哪些 Metrics 導致費用這麼高。
以下以 project_1 為例:
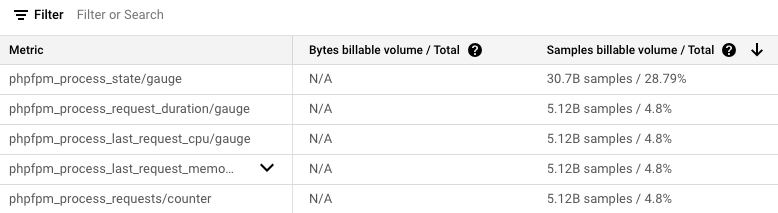
打開 Metrics Management 後,將時間選擇前 30 天(30d),與上面帳單選擇一樣,接著可以看到 Billable samples ingested 這邊,這裡就是指我們 30 天總共收了多少筆的 samples,也可以把他理解收了多少筆的 Metrics。也可以看到底下表格的 Samples billable volume 可以透過排序知道是誰使用最多。這邊的 B 代表 10 億,也就是 1000000000,所以我們上個月收了 1066 多億筆的 samples。
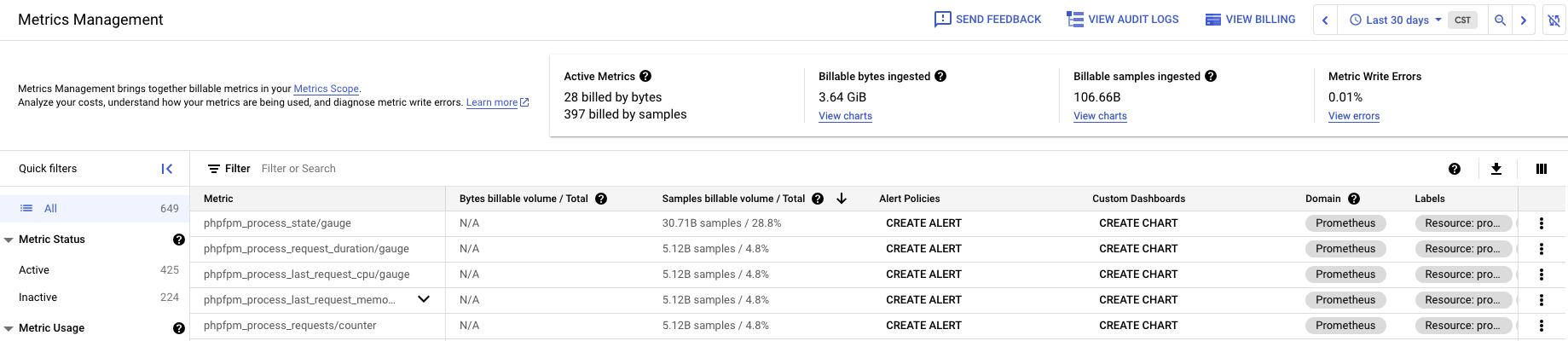
可以使用剛剛的腳本來計算 (沒錯,它也支援數字單位的轉換 xD),計算如下:

所以可以得知,帳單 Prometheus Samples Ingested 這個 SKU 會這麼高就是這邊的 Billable samples ingested 所導致,那我們現在可以依照下面的表格 Metrics 知道是哪個 Metrics 花錢最兇,在針對這些 Metrics 來進行調整,以達到減少費用的目的。
如何減少花費
我們可以從上面的表中知道,是 phpfpm_process_state/gauge 這個 metric,總共收了 30.71 B 也就是大約 1842.60 美元的花費是裡面最高的。所以我們就先這對如何減少這個 metric 來做說明:
要先知道 phpfpm_process_state/gauge 這個 metric 是怎麼來的呢?
首先我們可以從 metric 名稱知道它是 phpfpm 的 process 狀態。我們有開啟 Cluster 的 Managed Service for Prometheus,來使用 Google 管理的 Prometheus (GMP), 並在服務上面設定 phpfpm-exporter,並使用 PodMonitoring 來將 Pod 上的 metrics 接到 GMP 上。
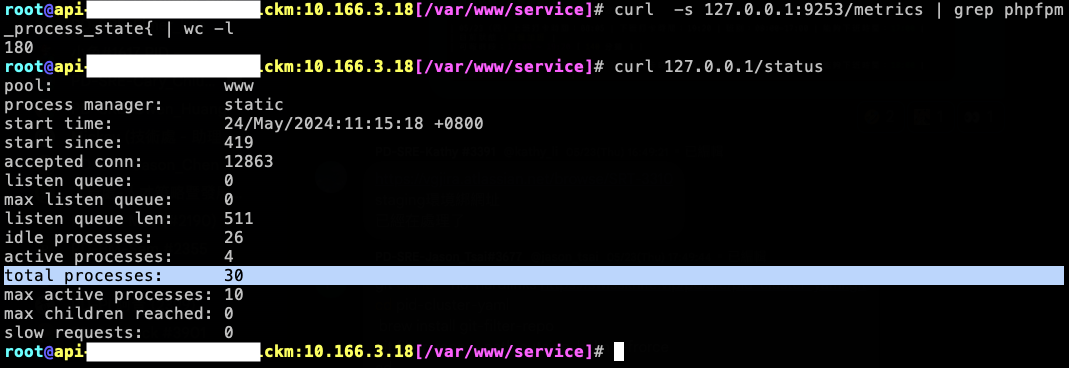
所以我們可以先到有 phpfpm-exporter 的 Pod 隨意的 Container 去看看這個 metrics,下 curl -s 127.0.0.1:9253/metrics 指令來查看 (請依照設定 port 去查看,這邊不詳細列出),可以看到會有很多 phpfpm-exporter 的 metrics。
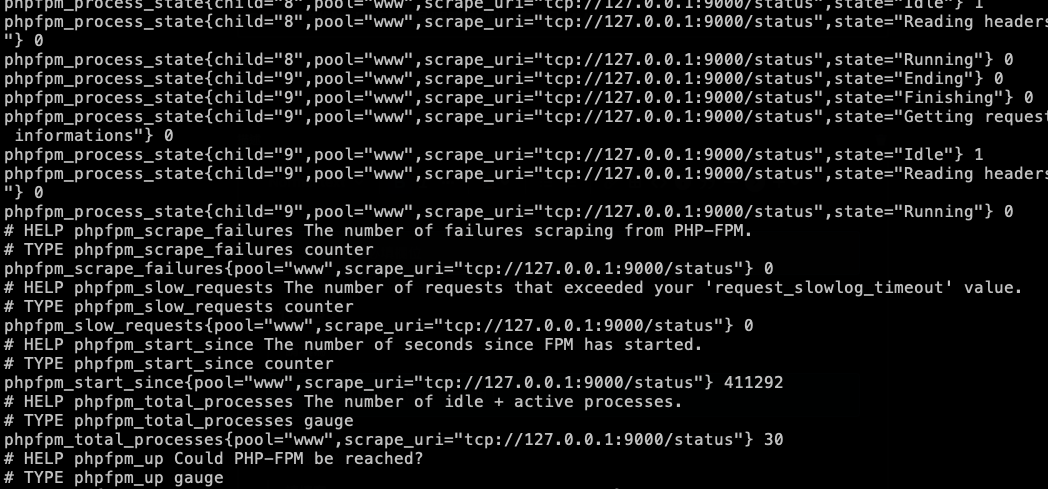
其中我們也可以找到 phpfpm_process_state 這個 metrics,這邊我們發現一個比較特別的事情,一般的 metrics 都只有一筆,但 phpfpm_process_state 它有 6 個狀態。

所以代表送到 GMP 的 metrics 也會比其他 phpfpm 相關的 metrics 還多 6 倍,這也可以解釋為什麼他是所有 metrics 裡面費用最高的,以及 phpfpm_process_state 費用是其他 phpfpm 像是:phpfpm_process_request_duration 的 6 倍了。
因此我們可以來計算一下費用,phpfpm_process_XXX 的 metrics 它會因為 process 的數量而改變,以 phpfpm_process_state 這個 metrics 來計算,計算公式就是:
process 數量 * 6 (上面說的6個狀態) * Pod 數量 * PodMonitoring interval 的秒數
(PodMonitoring interval 的秒數這個我們後續再說)
可以先看下圖,我們這個的 api 有 30 的 process,乘 6 個狀態,可以看到每次的搜集就會收集 180 筆的 phpfpm_process_state。
我們也可以透過 GCP 的 Metrics explorer 查詢到對應的數值。

剛剛提到的 PodMonitoring interval 的秒數,在 project_1 的 PodMonitoring 設定間隔是 60s,所以上面才不需要另外乘,但像是 project_1 的秒數都是 5s,所以我們還需要再多乘上 12 (60/5) 才是我們在 GCP 的 Metrics explorer 看到每分鐘的數量。
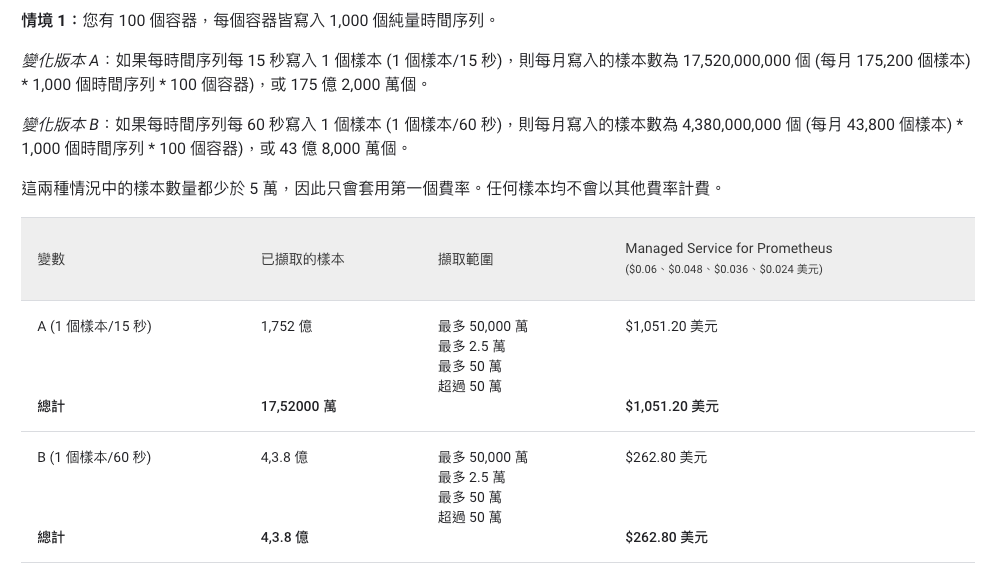
因此,我們可以得知費用會跟 process (範例的 metrics)、裡面的 metrics 有幾個、Pod 數量、 PodMonitoring 間隔時間有關,跟 Google 的文件說明也是一樣的
https://cloud.google.com/stackdriver/pricing?hl=zh-tw#pricing_examples_samples

所以要減少費用,可以調整上述影響 metrics 數量的變因,另一種方式就是,針對需要收集哪些 metrics 來做過濾,可以參考此文件:Get started with managed collection,過濾不要的 metrics ,避免送到 GMP 上,而有多餘的費用,我們可以在 PodMonitoring 上去來過濾要送出 metrics,如下:
apiVersion: monitoring.googleapis.com/v1
kind: PodMonitoring
metadata:
name: {{ $.Values.deployment.name }}
namespace: {{ $.Release.Namespace }}
spec:
selector:
matchLabels:
app: {{ $.Values.deployment.name }}
endpoints:
- port: metrics
interval: {{ .endpoints.metrics_interval_sec }}
metricRelabeling:
- action: drop
regex: phpfpm_process_state
sourceLabels: [__name__]透過 metricRelabeling 使用 drop 方式,搭配正規表示法來過濾 name 是 phpfpm_process_state 的 metrics,另外也可以使用 keep 的方式,決定要送什麼到 GMP 上。
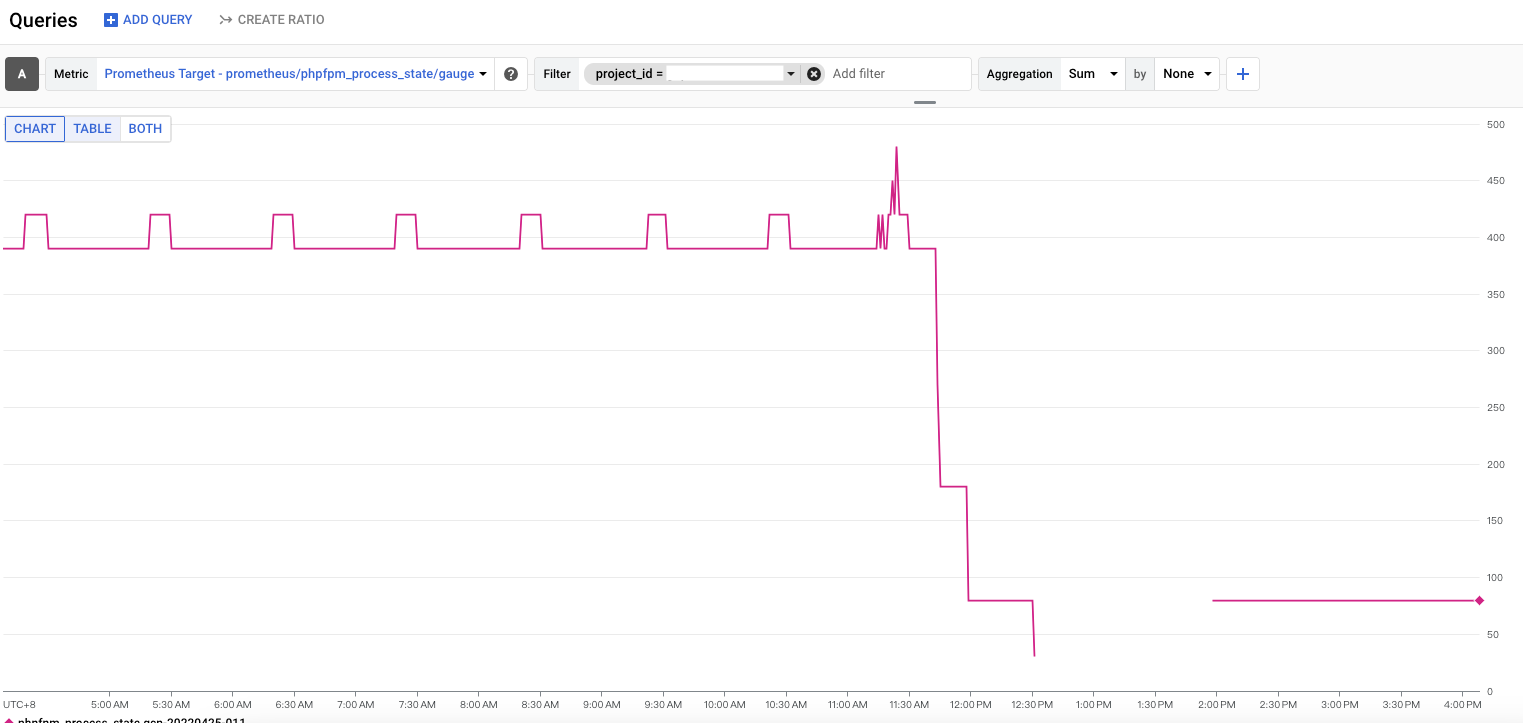
上圖就是在 PodMonitoring 上新增 drop 來過濾 phpfpm_process_state,也可以看 Samples billable volume 變成 0 Sample,就代表我們把這個 metrics 給過濾掉拉~~~ 也就可以省錢囉xDD
