GKE DNS 使用 Cloud DNS + NodeLocal DNSCache 運作測試
最近在評估要將公司內的 EndPoint 都改成 Cloud DNS 的 Private Zone (打造內部的 internal dns 服務機制),到時候 DNS 解析的請求會比以往還要多,所以需要先測試評估 GKE 內的 DNS 解析方案,避免再次發生 Pod 出現 cURL error 6: Could not resolve host,此篇文章測試的是: Cloud DNS + NodeLocal DNSCache 的運作。
首先,先建立一個 dns-test pod 程式連結 以及 nginx 的 pod + svc 程式連結,會分別測試
叢集內部 cluster.local (nginx-svc.default.svc.cluster.local)
internal-dns 使用 cloud dns private (aaa.test-audit.com)
外部 dns (ifconfig.me)
並使用 nslookup 腳本進行確認回傳 DNS 解析,每一次測試都會重新建立 KubeDNS、NodeLocal DNSCache Pod
相關程式以及 Prometheus、Grafana 的設定可以參考:https://github.com/880831ian/gke-dns
在建立完 Cluster 後,可以先觀察在 Cloud DNS 是否新增的 Private Zone
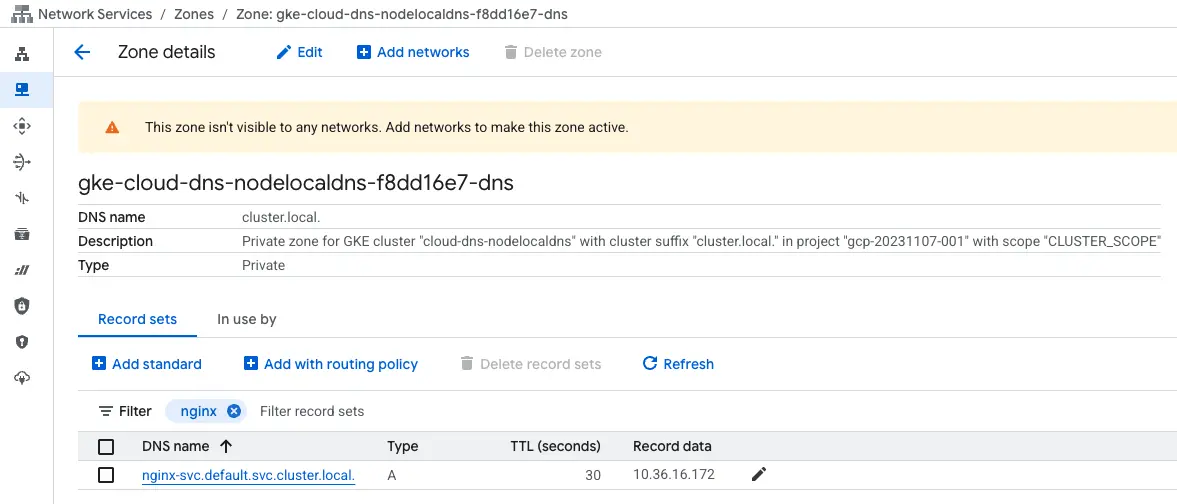
由於裡面有很多的 Record,我們先搜尋下面會用到的 nginx-svc.default.svc.cluster.local 來當作範例
叢集內部 cluster.local
一樣會觀察 KubeDNS Pod Metrics,因為就算開啟 Cloud DNS 後,KubeDNS 還是會留著

NodeLocal DNSCache Prometheus 監控設定參數:zones="cluster.local."
- 相關 Prometheus 監控指標:
coredns_cache_requests_total{job="cloud-dns-nodelocaldns", zones="cluster.local."}
coredns_cache_entries{job="cloud-dns-nodelocaldns", zones="cluster.local."}
coredns_cache_hits_total{job="cloud-dns-nodelocaldns", zones="cluster.local."}
coredns_cache_misses_total{job="cloud-dns-nodelocaldns", zones="cluster.local."}
kubedns_dnsmasq_hits{job="kubedns-dns"}
kubedns_dnsmasq_misses{job="kubedns-dns"}測試腳本:
#!/bin/bash
get_taiwan_time() {
# 獲取當前 UTC 時間的 Unix 時間戳
UTC_TIMESTAMP=$(date -u +%s)
# 加上 8 小時 (台灣時間是 UTC+8)
TAIPEI_TIMESTAMP=$((UTC_TIMESTAMP + 28800))
# 將時間戳轉換為格式化後的日期時間
date -d "@$TAIPEI_TIMESTAMP" "+%Y-%m-%d %H:%M:%S"
}
DOMAIN="nginx-svc.default.svc.cluster.local"
EXPECTED_IP="10.36.16.172"
START_TIME=$(get_taiwan_time)
COUNT=10000
SUCCESS_COUNT=0
FAIL_COUNT=0
echo "== NSLOOKUP TEST START: $START_TIME ==" | tee -a nslookup_full.log
for i in $(seq 1 "$COUNT"); do
OUTPUT=$(nslookup "$DOMAIN" 2>&1)
ADDR_LINE=$(echo "$OUTPUT" | grep -E '^Address:')
if [[ "$ADDR_LINE" == *"$EXPECTED_IP"* ]]; then
SUCCESS_COUNT=$((SUCCESS_COUNT + 1))
else
FAIL_COUNT=$((FAIL_COUNT + 1))
fi
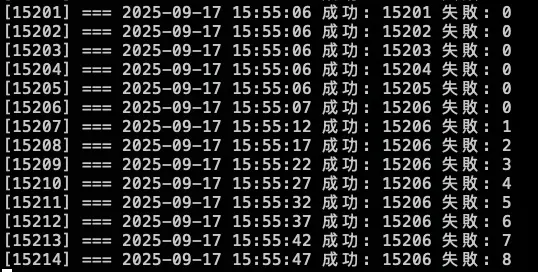
echo "[$i] === $(get_taiwan_time) 成功: $SUCCESS_COUNT 失敗: $FAIL_COUNT"
done
END_TIME=$(get_taiwan_time)
echo "== NSLOOKUP TEST END: $END_TIME ==" | tee -a nslookup_full.log
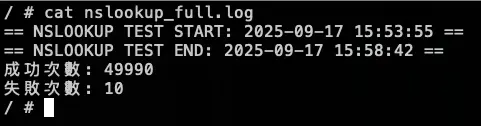
echo "成功次數: $SUCCESS_COUNT" | tee -a nslookup_full.log
echo "失敗次數: $FAIL_COUNT" | tee -a nslookup_full.log10.36.16.172 是 nginx-svc Cluster IP
需要先確認 nginx-svc 的 IP 是多少,然後修改腳本中的 EXPECTED_IP 變數。
測試腳本
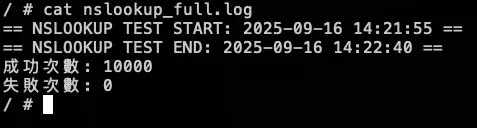
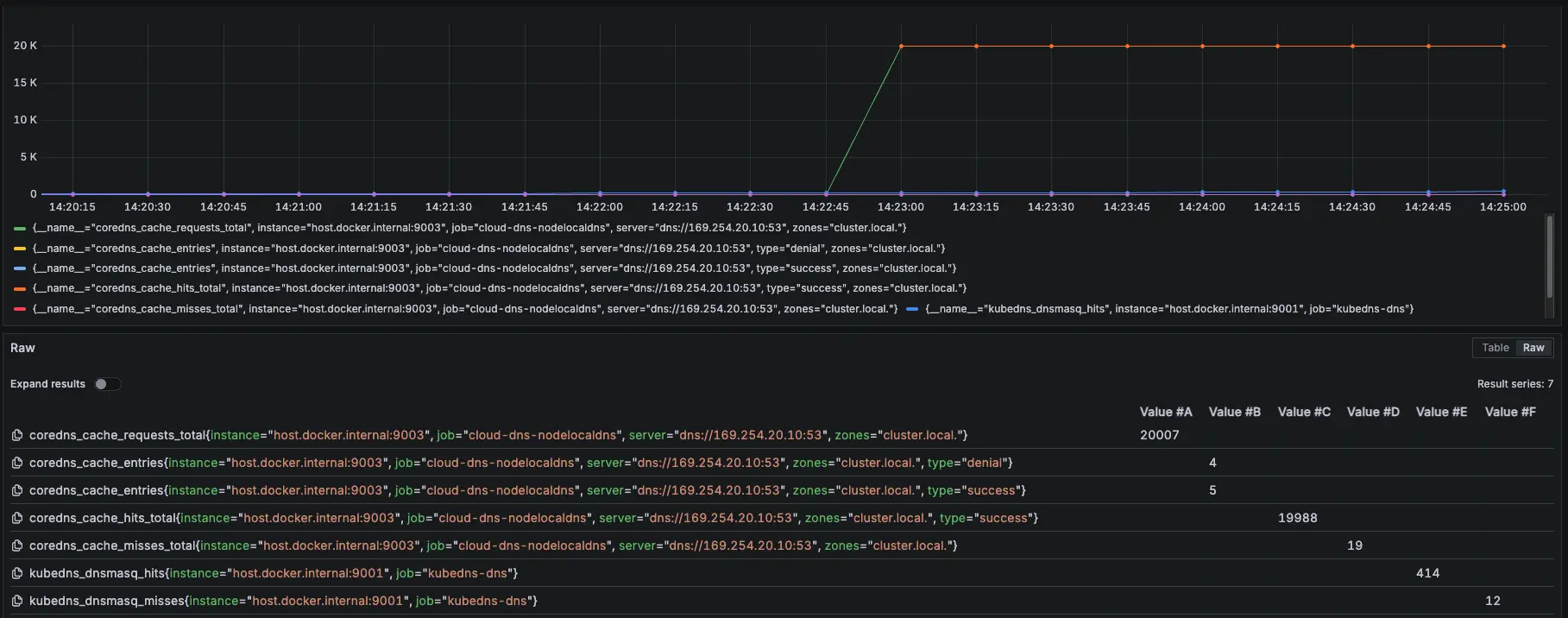
測試結果:
結論
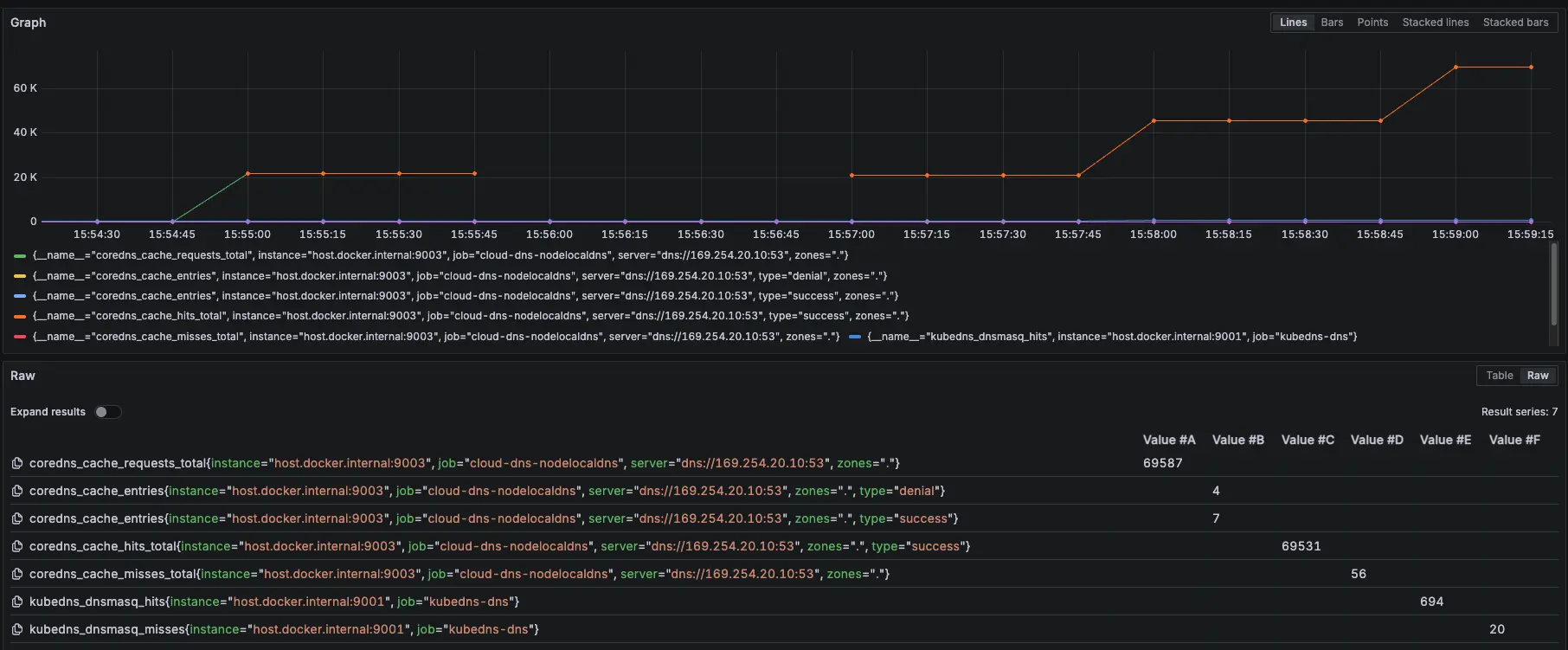
可以觀察 NodeLocal DNSCache hit 跟 request 都有持續上升,但與 KubeDNS + NodeLocal DNSCache 模式 metrics 比較不一樣的地方是:Server 從 KubeDNS IP 變成 169.254.20.10,可以回去看:GKE KubeDNS + NodeLocal DNSCache 運作測試 #叢集內部 cluster.local
模擬 KubeDNS Pod 異常
接下來會在測試中,將 KubeDNS 調整到 0 顆,再開回去,觀察此模式對於 KubeDNS 的依賴
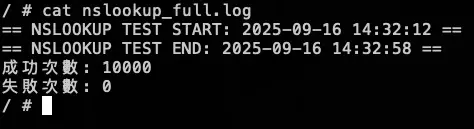
測試結果:
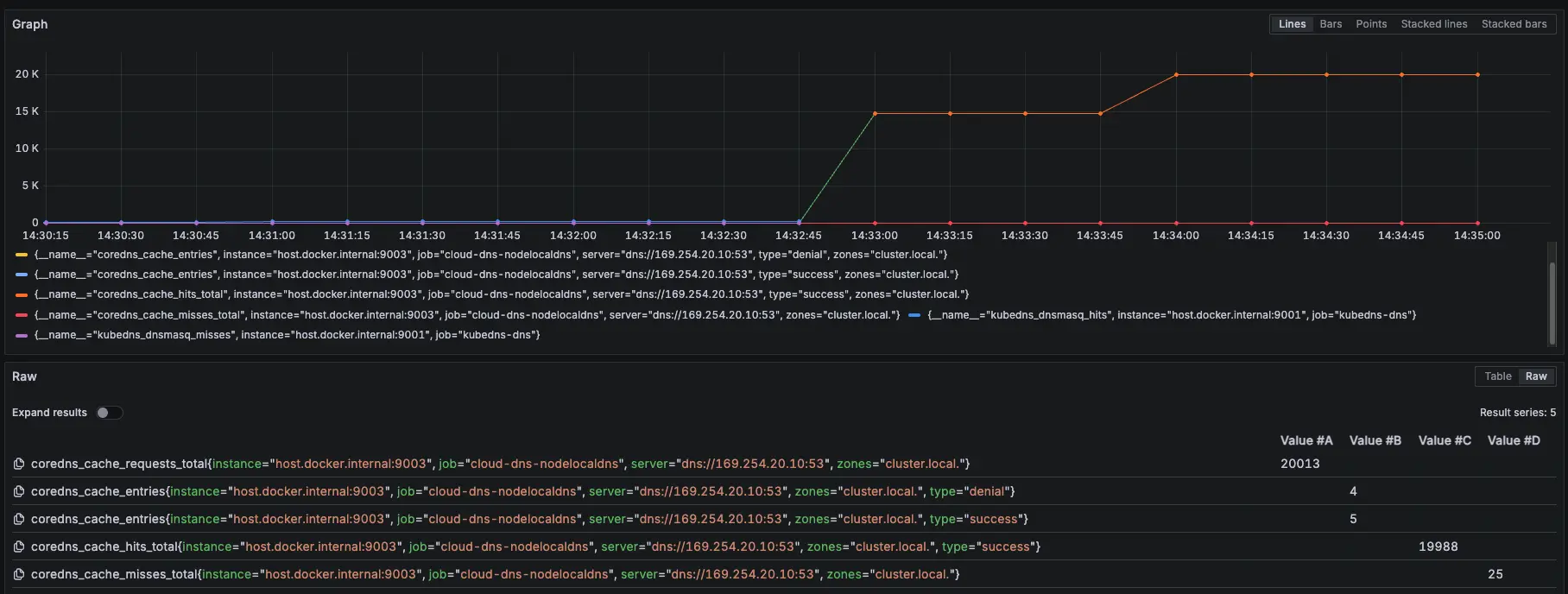
結論
大約在 2000 筆請求時左右將 KubeDNS 關成 0 顆,可以看到 NodeLocal DNSCache 有往上漲,也因為我們已經改用 Cloud DNS 來解析叢集內部 DNS,所以就算關閉 KubeDNS 也不會有影響,因為 NodeLocal DNSCache 會去問 Cloud DNS,並 Cache 在 NodeLocal DNSCache
模擬 NodeLocal DNSCache Pod 異常
接下來我們測試最後一個情境,故意用壞 NodeLocal DNSCache 服務,觀察此模式對於 NodeLocal DNSCache 的依賴
測試情境:
先調整 COUNT 參數變成 50000
先跑 15000 筆有 NodeLocal DNSCache,然後使用以下指令讓 NodeLocal DNSCache 無法使用
kubectl patch daemonset node-local-dns -n kube-system --type='strategic' -p '{"spec":{"template":{"spec":{"nodeSelector":{"this-label-does-not-exist-on-any-node":"true"}}}}}'等待約 30000 筆時,使用以下指令恢復 NodeLocal DNSCache
kubectl patch daemonset node-local-dns -n kube-system --type='strategic' -p '{"spec":{"template":{"spec":{"nodeSelector":null}}}}'測試結果:
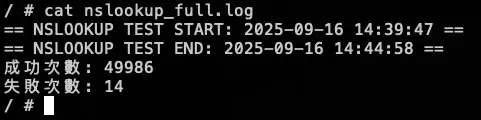
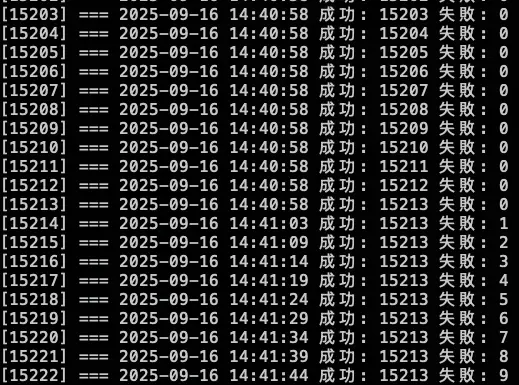
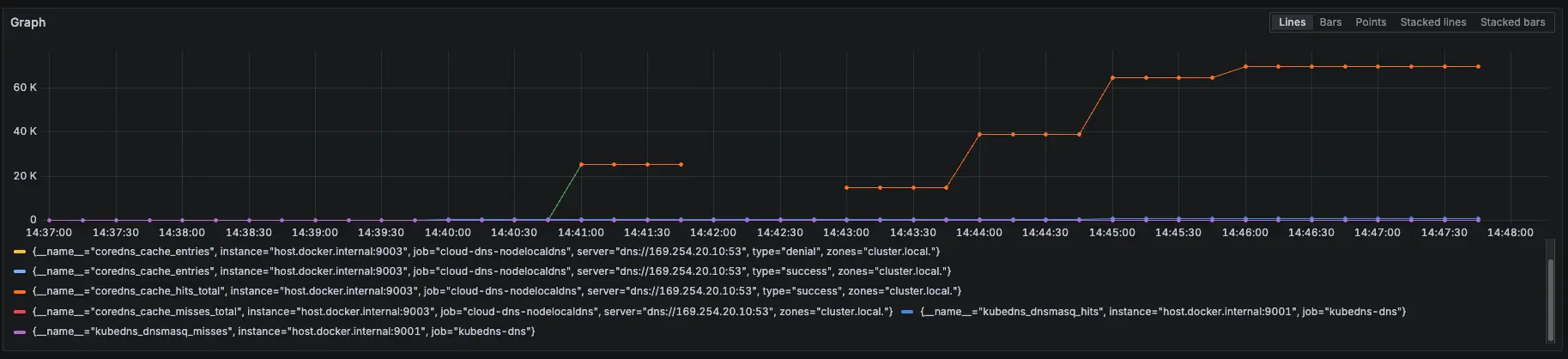
結論
發現當 NodeLocal DNSCache 掛了後,會直接卡住 (時間每五秒是因為打不到 timeout),也不會切換到 KubeDNS 來做解析,所以最後測試沒有等到 30000 筆才下指令恢復 NodeLocal DNSCache,先提早下指令讓 NodeLocal DNSCache 正常,等到恢復,解析就正常了
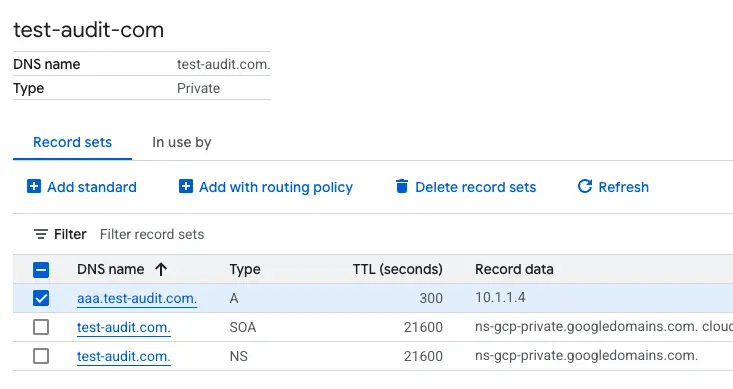
Internal DNS (Cloud DNS Private)
先建立一個 cloud dns private,以下範例是 aaa.test-audit.com > 10.1.1.4,並將此 use VPC 與 GKE 的 VPC 打通
NodeLocal DNSCache Prometheus 監控設定參數:zones="."
- 相關 Prometheus 監控指標:
coredns_cache_requests_total{job="cloud-dns-nodelocaldns", zones="."}
coredns_cache_entries{job="cloud-dns-nodelocaldns", zones="."}
coredns_cache_hits_total{job="cloud-dns-nodelocaldns", zones="."}
coredns_cache_misses_total{job="cloud-dns-nodelocaldns", zones="."}
kubedns_dnsmasq_hits{job="kubedns-dns"}
kubedns_dnsmasq_misses{job="kubedns-dns"}測試腳本:
#!/bin/bash
get_taiwan_time() {
# 獲取當前 UTC 時間的 Unix 時間戳
UTC_TIMESTAMP=$(date -u +%s)
# 加上 8 小時 (台灣時間是 UTC+8)
TAIPEI_TIMESTAMP=$((UTC_TIMESTAMP + 28800))
# 將時間戳轉換為格式化後的日期時間
date -d "@$TAIPEI_TIMESTAMP" "+%Y-%m-%d %H:%M:%S"
}
DOMAIN="aaa.test-audit.com"
EXPECTED_IP="10.1.1.4"
START_TIME=$(get_taiwan_time)
COUNT=10000
SUCCESS_COUNT=0
FAIL_COUNT=0
echo "== NSLOOKUP TEST START: $START_TIME ==" | tee -a nslookup_full.log
for i in $(seq 1 "$COUNT"); do
OUTPUT=$(nslookup "$DOMAIN" 2>&1)
ADDR_LINE=$(echo "$OUTPUT" | grep -E '^Address:')
if [[ "$ADDR_LINE" == *"$EXPECTED_IP"* ]]; then
SUCCESS_COUNT=$((SUCCESS_COUNT + 1))
else
FAIL_COUNT=$((FAIL_COUNT + 1))
fi
echo "[$i] === $(get_taiwan_time) 成功: $SUCCESS_COUNT 失敗: $FAIL_COUNT"
done
END_TIME=$(get_taiwan_time)
echo "== NSLOOKUP TEST END: $END_TIME ==" | tee -a nslookup_full.log
echo "成功次數: $SUCCESS_COUNT" | tee -a nslookup_full.log
echo "失敗次數: $FAIL_COUNT" | tee -a nslookup_full.log10.1.1.4 是隨機亂取的 IP,只是為了確認 domain 是否能夠正常解析
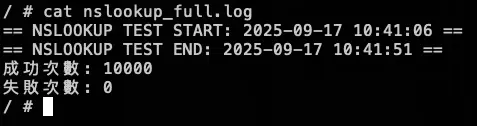
測試腳本
測試結果:
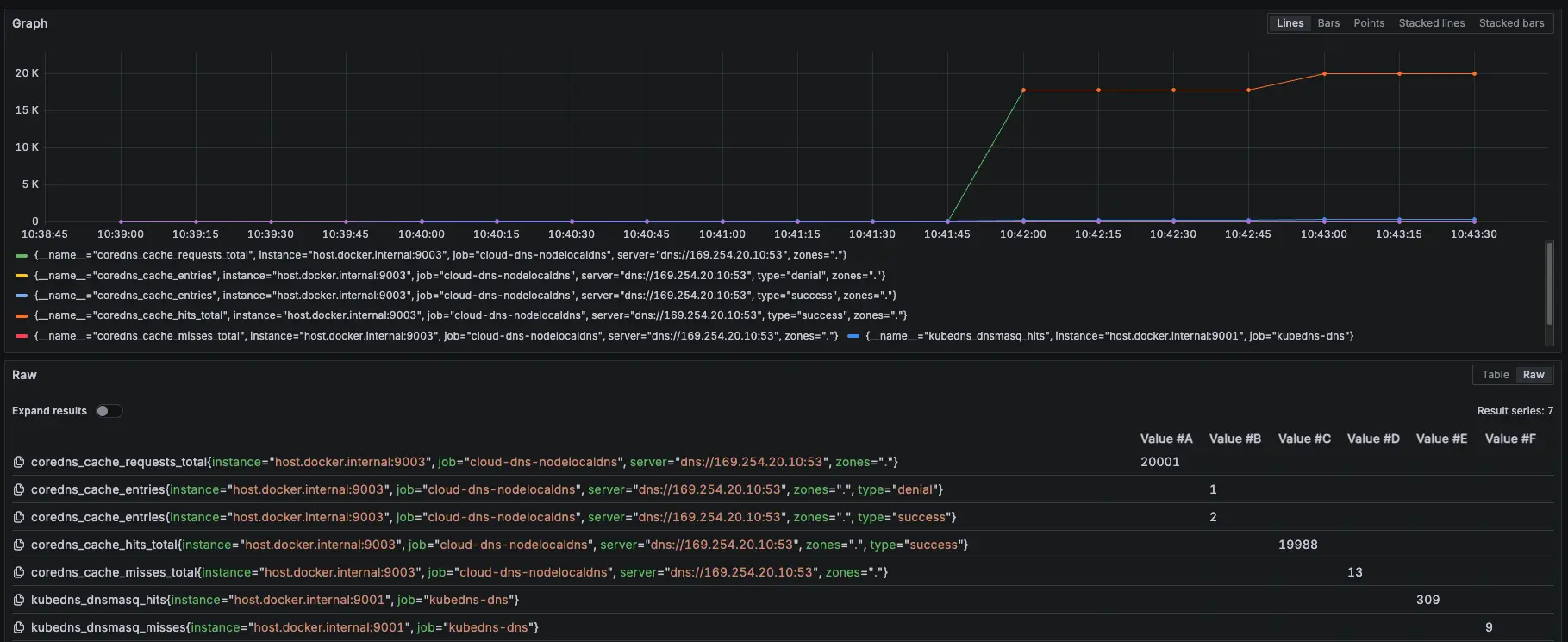
結論
可以觀察 NodeLocal DNSCache hit 跟 request 都有持續上升,但與 KubeDNS + NodeLocal DNSCache 模式 metrics 比較不一樣的地方是:Server 從 KubeDNS IP 變成 169.254.20.10,可以回去看:GKE KubeDNS + NodeLocal DNSCache 運作測試 #Internal DNS (Cloud DNS Private)
模擬 KubeDNS Pod 異常
接下來會在測試中,將 KubeDNS 調整到 0 顆,再開回去,觀察此模式對於 KubeDNS 的依賴
測試結果:
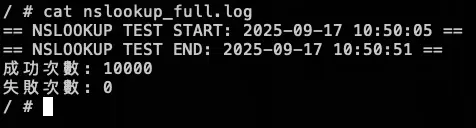
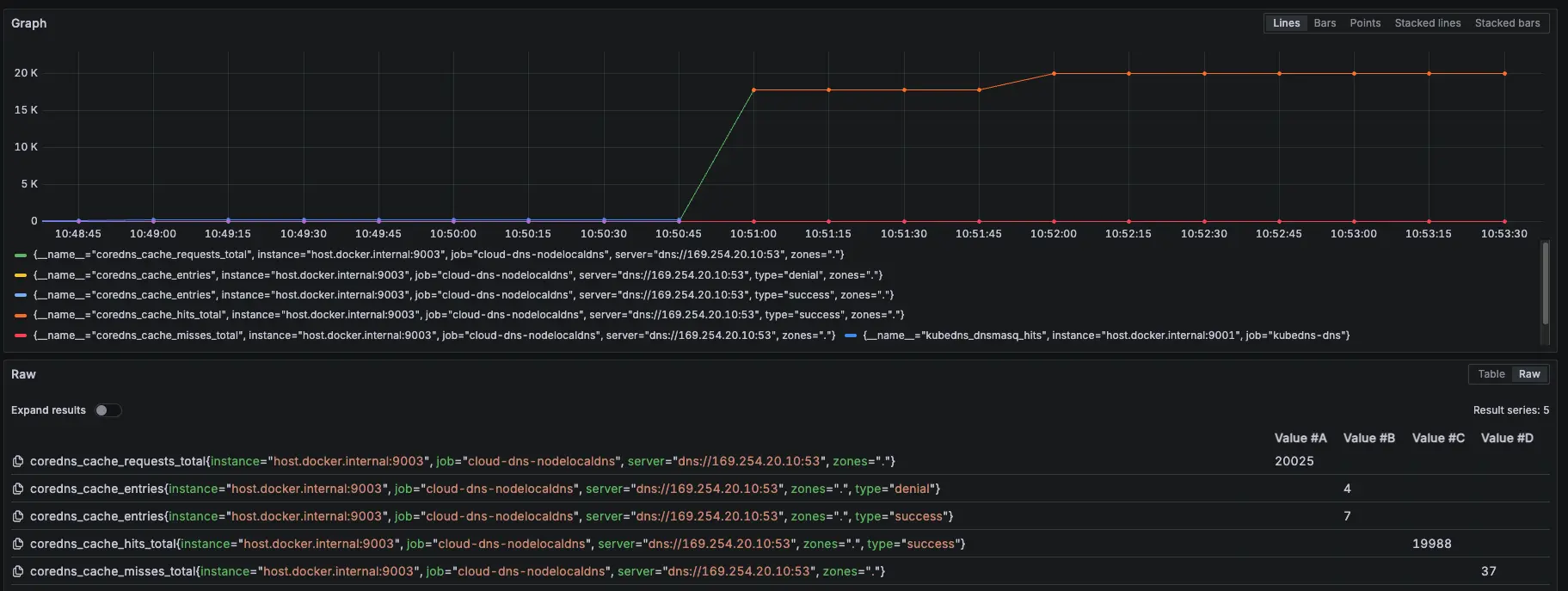
結論
大約在 2000 筆請求時左右將 KubeDNS 關成 0 顆,可以看到 NodeLocal DNSCache 有往上漲,也因為我們已經改用 Cloud DNS 來解析 internal-dns DNS,所以就算關閉 KubeDNS 也不會有影響,因為 NodeLocal DNSCache 會去問 Cloud DNS,並 Cache 在 NodeLocal DNSCache
模擬 NodeLocal DNSCache Pod 異常
接下來我們測試最後一個情境,故意用壞 NodeLocal DNSCache 服務,觀察此模式對於 NodeLocal DNSCache 的依賴
測試情境:
先調整 COUNT 參數變成 50000
先跑 15000 筆有 NodeLocal DNSCache,然後使用以下指令讓 NodeLocal DNSCache 無法使用
kubectl patch daemonset node-local-dns -n kube-system --type='strategic' -p '{"spec":{"template":{"spec":{"nodeSelector":{"this-label-does-not-exist-on-any-node":"true"}}}}}'等待約 30000 筆時,使用以下指令恢復 NodeLocal DNSCache
kubectl patch daemonset node-local-dns -n kube-system --type='strategic' -p '{"spec":{"template":{"spec":{"nodeSelector":null}}}}'測試結果:
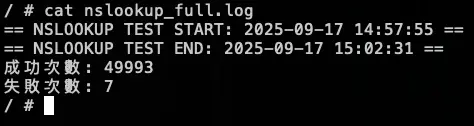
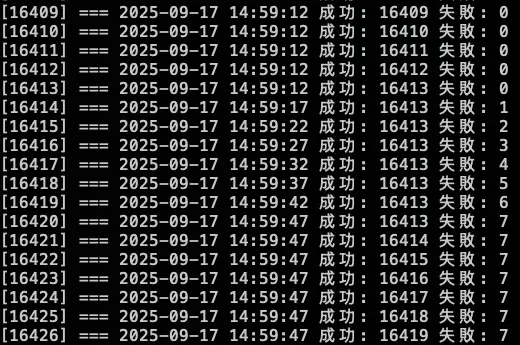

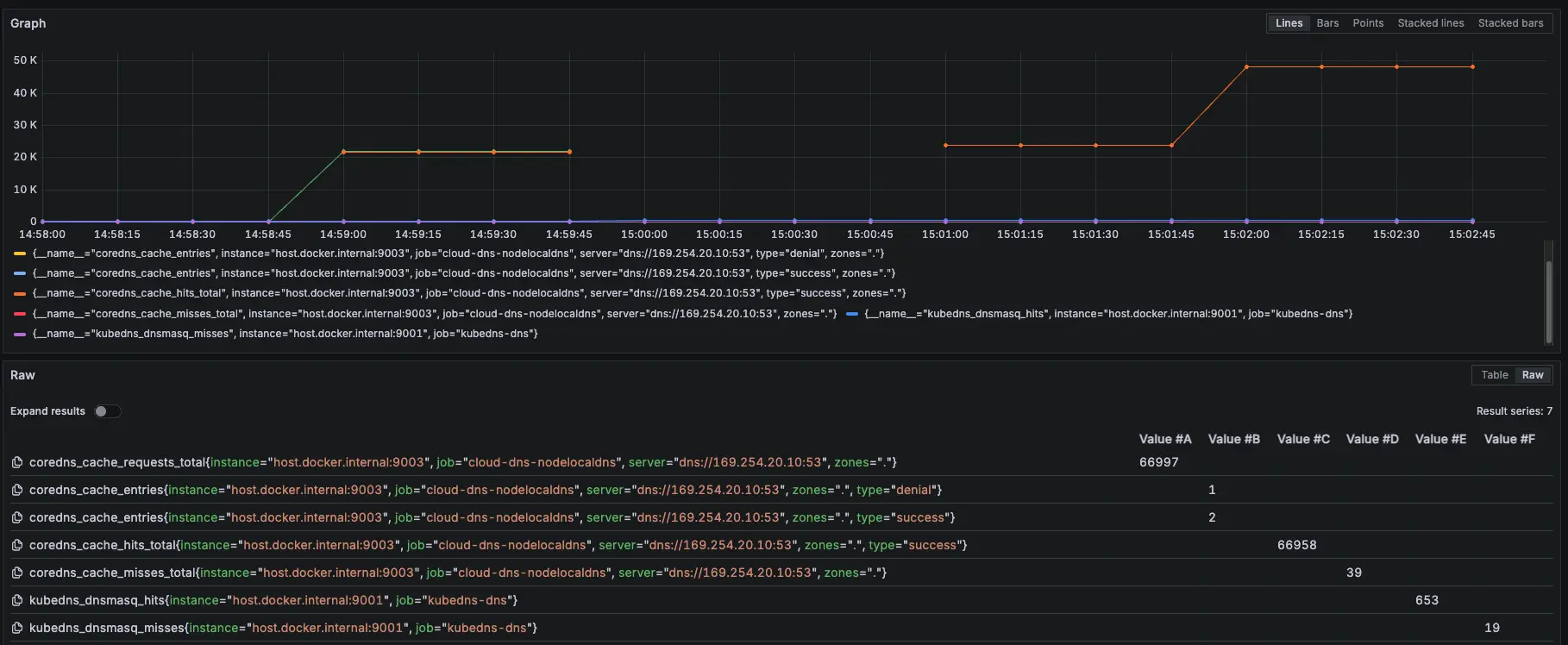
結論
發現當 NodeLocal DNSCache 掛了後,會直接卡住 (時間每五秒是因為打不到 timeout),也不會切換到 KubeDNS 來做解析,所以最後測試沒有等到 30000 筆才下指令恢復 NodeLocal DNSCache,先提早下指令讓 NodeLocal DNSCache 正常,等到恢復,解析就正常了
外部 DNS (ifconfig.me)
NodeLocal DNSCache Prometheus 監控設定參數:zones="."
- 相關 Prometheus 監控指標:
coredns_cache_requests_total{job="cloud-dns-nodelocaldns", zones="."}
coredns_cache_entries{job="cloud-dns-nodelocaldns", zones="."}
coredns_cache_hits_total{job="cloud-dns-nodelocaldns", zones="."}
coredns_cache_misses_total{job="cloud-dns-nodelocaldns", zones="."}
kubedns_dnsmasq_hits{job="kubedns-dns"}
kubedns_dnsmasq_misses{job="kubedns-dns"}測試腳本:
#!/bin/bash
get_taiwan_time() {
# 獲取當前 UTC 時間的 Unix 時間戳
UTC_TIMESTAMP=$(date -u +%s)
# 加上 8 小時 (台灣時間是 UTC+8)
TAIPEI_TIMESTAMP=$((UTC_TIMESTAMP + 28800))
# 將時間戳轉換為格式化後的日期時間
date -d "@$TAIPEI_TIMESTAMP" "+%Y-%m-%d %H:%M:%S"
}
DOMAIN="ifconfig.me"
EXPECTED_IP="34.160.111.145"
START_TIME=$(get_taiwan_time)
COUNT=10000
SUCCESS_COUNT=0
FAIL_COUNT=0
echo "== NSLOOKUP TEST START: $START_TIME ==" | tee -a nslookup_full.log
for i in $(seq 1 "$COUNT"); do
OUTPUT=$(nslookup "$DOMAIN" 2>&1)
ADDR_LINE=$(echo "$OUTPUT" | grep -E '^Address:')
if [[ "$ADDR_LINE" == *"$EXPECTED_IP"* ]]; then
SUCCESS_COUNT=$((SUCCESS_COUNT + 1))
else
FAIL_COUNT=$((FAIL_COUNT + 1))
fi
echo "[$i] === $(get_taiwan_time) 成功: $SUCCESS_COUNT 失敗: $FAIL_COUNT"
done
END_TIME=$(get_taiwan_time)
echo "== NSLOOKUP TEST END: $END_TIME ==" | tee -a nslookup_full.log
echo "成功次數: $SUCCESS_COUNT" | tee -a nslookup_full.log
echo "失敗次數: $FAIL_COUNT" | tee -a nslookup_full.log34.160.111.145 是 ifconfig.me 的 IP,只是為了確認 domain 是否能夠正常解析
測試腳本
測試結果:
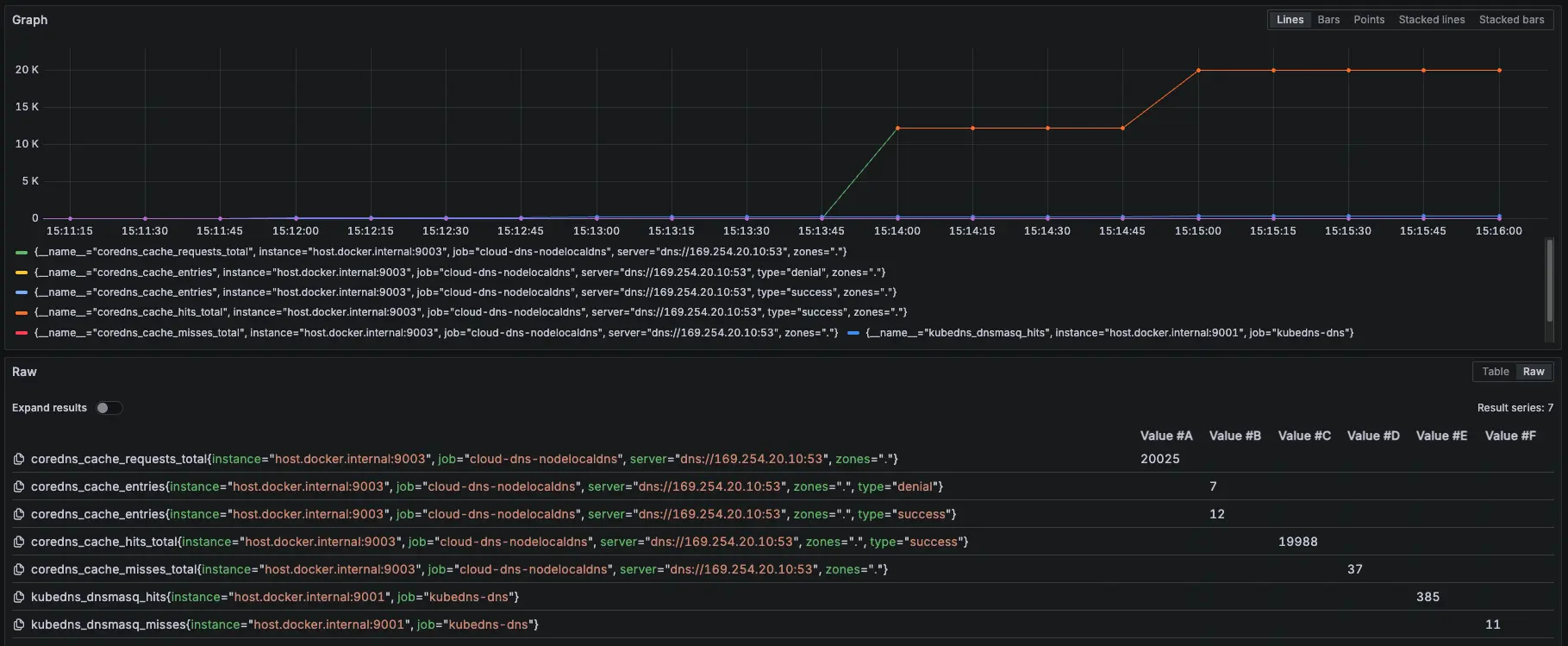
結論
可以觀察 NodeLocal DNSCache hit 跟 request 都有持續上升,但與 KubeDNS + NodeLocal DNSCache 模式 metrics 比較不一樣的地方是:Server 從 KubeDNS IP 變成 169.254.20.10,可以回去看: GKE KubeDNS + NodeLocal DNSCache 運作測試 #外部 DNS (ifconfig.me)
模擬 KubeDNS Pod 異常
接下來會在測試中,將 KubeDNS 調整到 0 顆,再開回去,觀察此模式對於 KubeDNS 的依賴
測試結果:
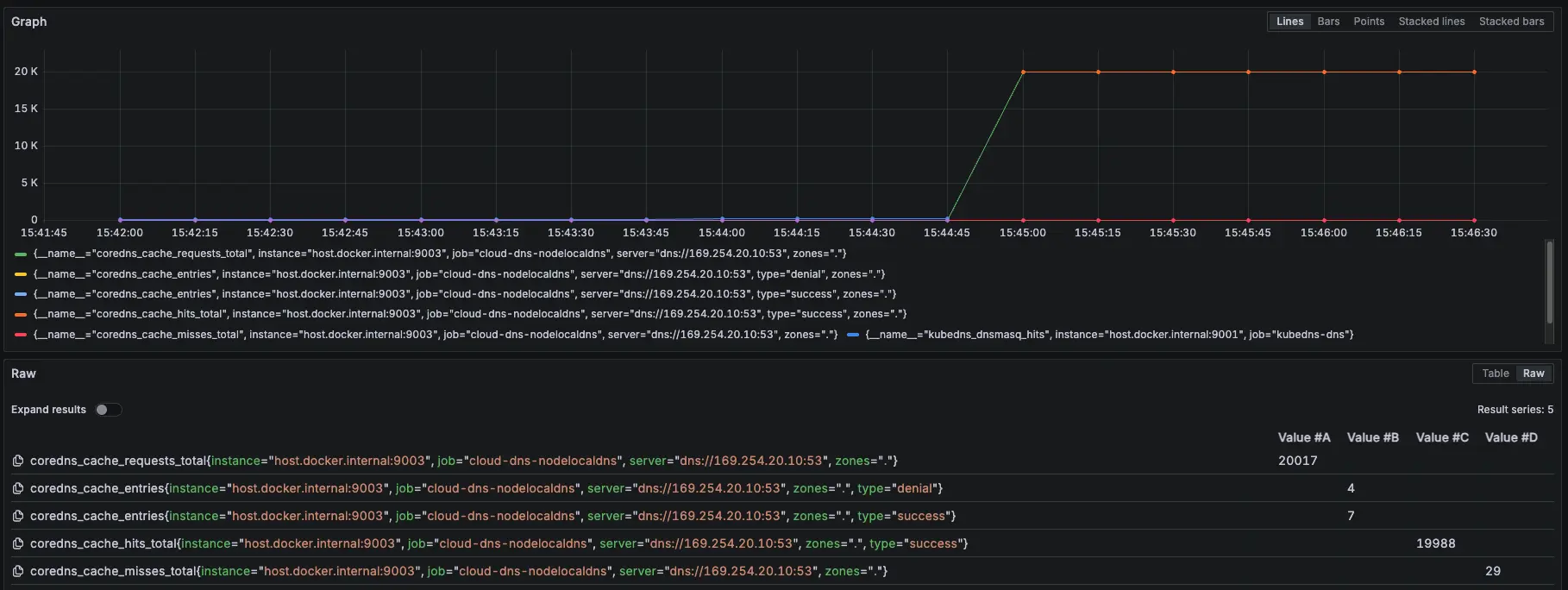
結論
大約在 2000 筆請求時左右將 KubeDNS 關成 0 顆,可以看到 NodeLocal DNSCache 有往上漲,也因為我們已經改用 Cloud DNS 來解析 internal-dns DNS,所以就算關閉 KubeDNS 也不會有影響,因為 NodeLocal DNSCache 會去問 Cloud DNS,並 Cache 在 NodeLocal DNSCache
模擬 NodeLocal DNSCache Pod 異常
接下來我們測試最後一個情境,故意用壞 NodeLocal DNSCache 服務,觀察此模式對於 NodeLocal DNSCache 的依賴
測試情境:
先調整 COUNT 參數變成 50000
先跑 15000 筆有 NodeLocal DNSCache,然後使用以下指令讓 NodeLocal DNSCache 無法使用
kubectl patch daemonset node-local-dns -n kube-system --type='strategic' -p '{"spec":{"template":{"spec":{"nodeSelector":{"this-label-does-not-exist-on-any-node":"true"}}}}}'等待約 30000 筆時,使用以下指令恢復 NodeLocal DNSCache
kubectl patch daemonset node-local-dns -n kube-system --type='strategic' -p '{"spec":{"template":{"spec":{"nodeSelector":null}}}}'測試結果:

結論
發現當 NodeLocal DNSCache 掛了後,會直接卡住 (時間每五秒是因為打不到 timeout),也不會切換到 KubeDNS 來做解析,所以最後測試沒有等到 30000 筆才下指令恢復 NodeLocal DNSCache,先提早下指令讓 NodeLocal DNSCache 正常,等到恢復,解析就正常了
k6 測試
額外在另一個 cluster 建立 nginx deployment 開 5 個 pod 以及 svc 改成 lb (L4),然後在 cloud dns 的 test-audit-com 設定 nginx-lb-internal.test-audit.com 解析到內網的 svc (10.156.16.19)
使用 k6 測試 KubeDNS + NodeLocal DNSCache 模式下 IP 跟 DNS 的差異
相關程式可以參考:https://github.com/880831ian/gke-dns
這邊測試的 Node 是用 e2-medium 而非 c3d-standard-4
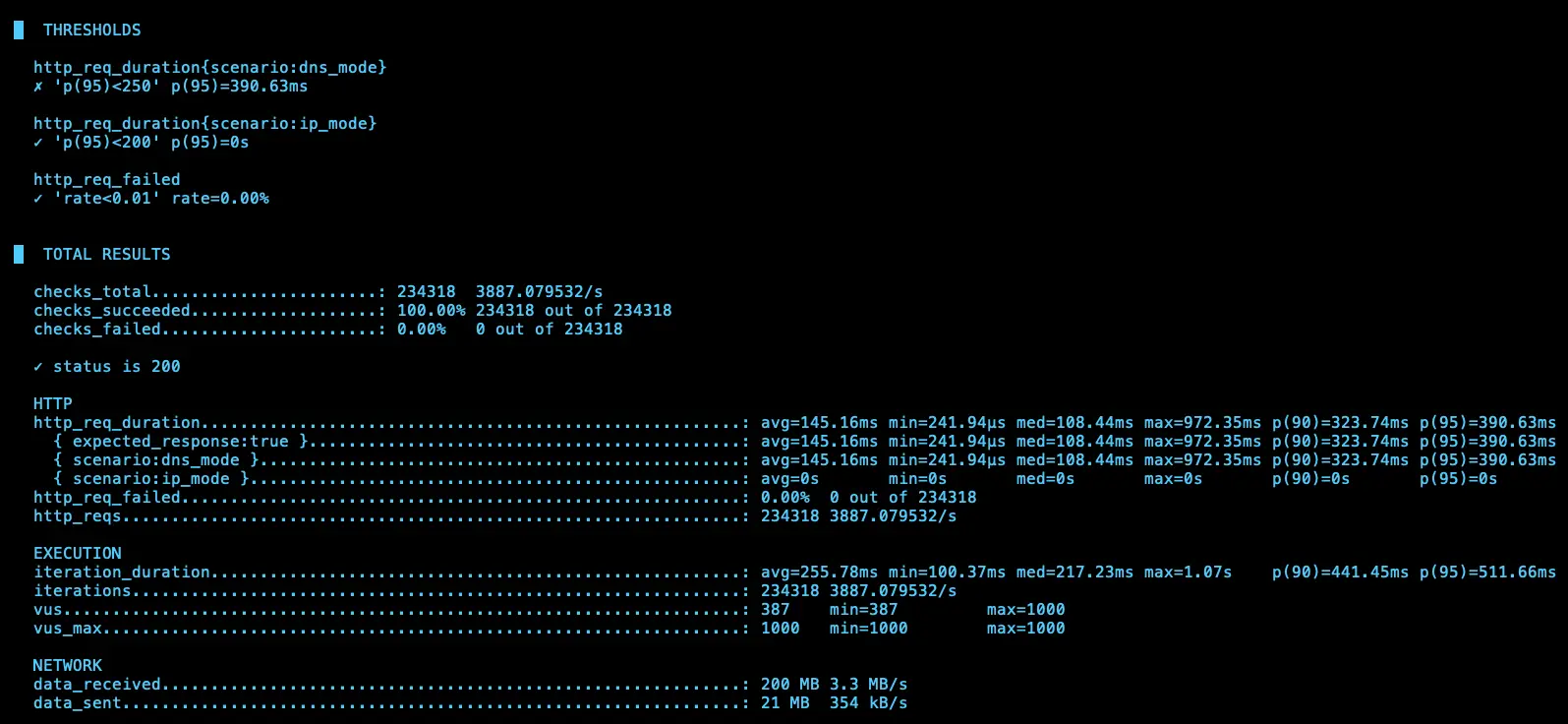
第一次測試
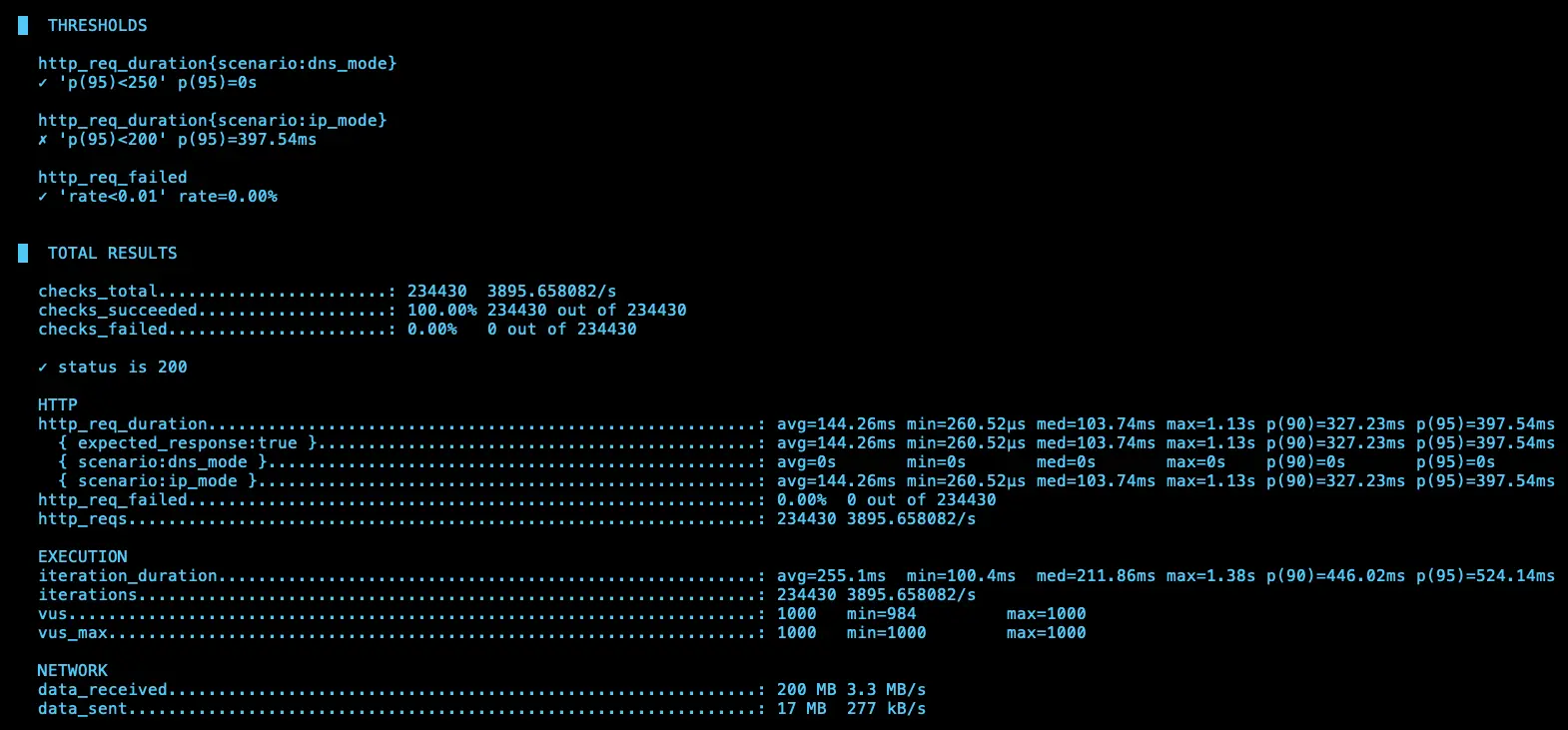
IP (avg=144.26ms / 3895 RPS)、DNS (avg=145.16ms / 3887 RPS)
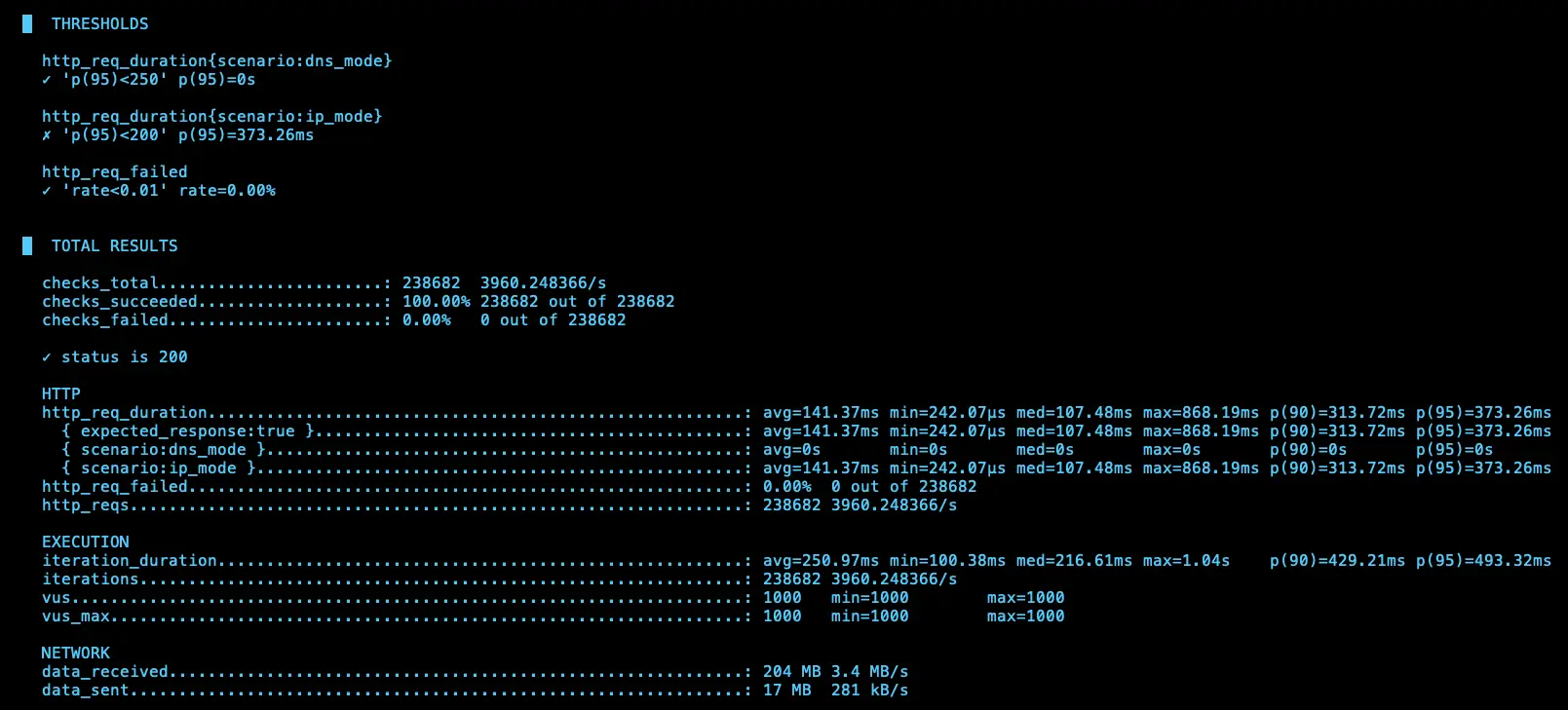
第二次測試
IP (avg=141.37ms / 3960 RPS)、DNS (avg=144.9ms / 3806 RPS)
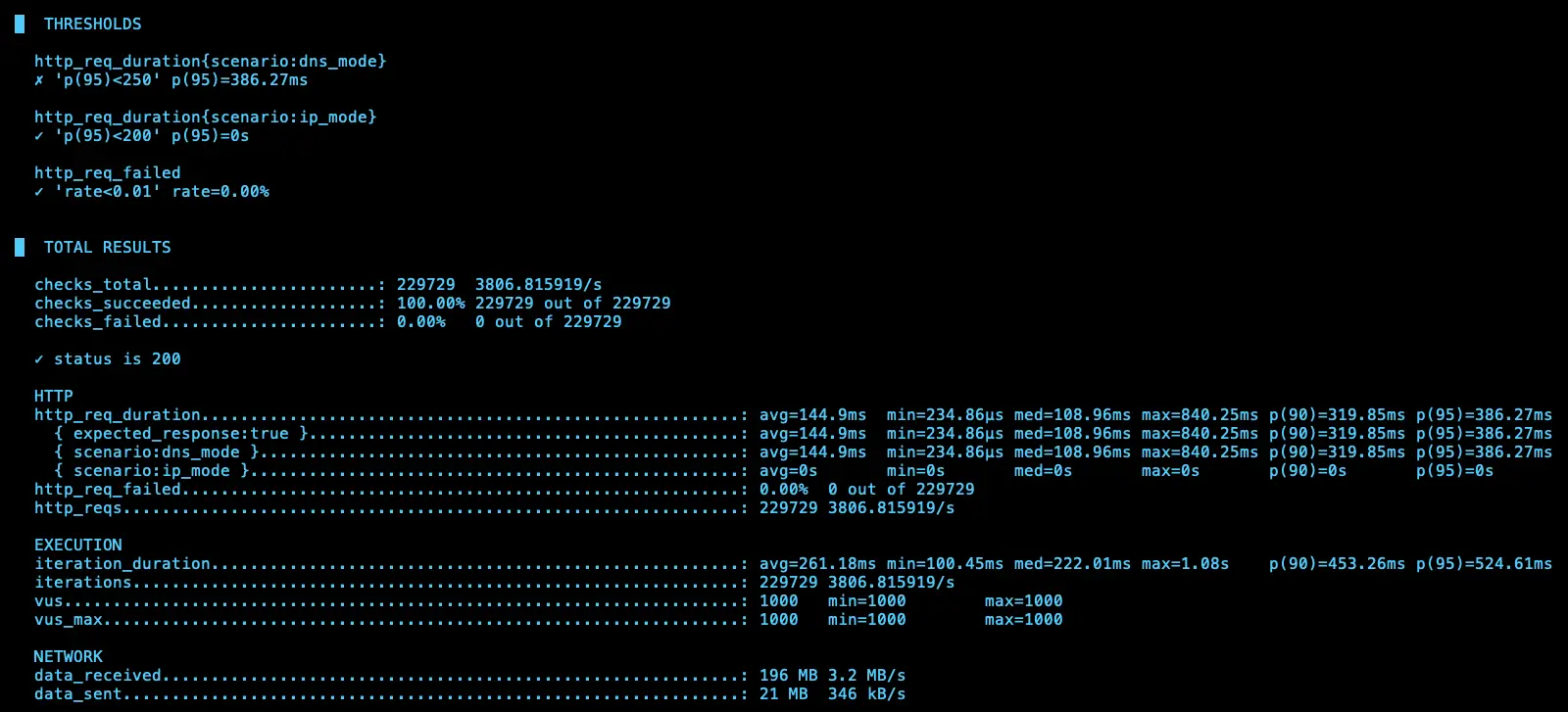
第三次測試
IP (avg=172.8ms / 2959 RPS)、DNS (avg=150.34ms / 3715 RPS)
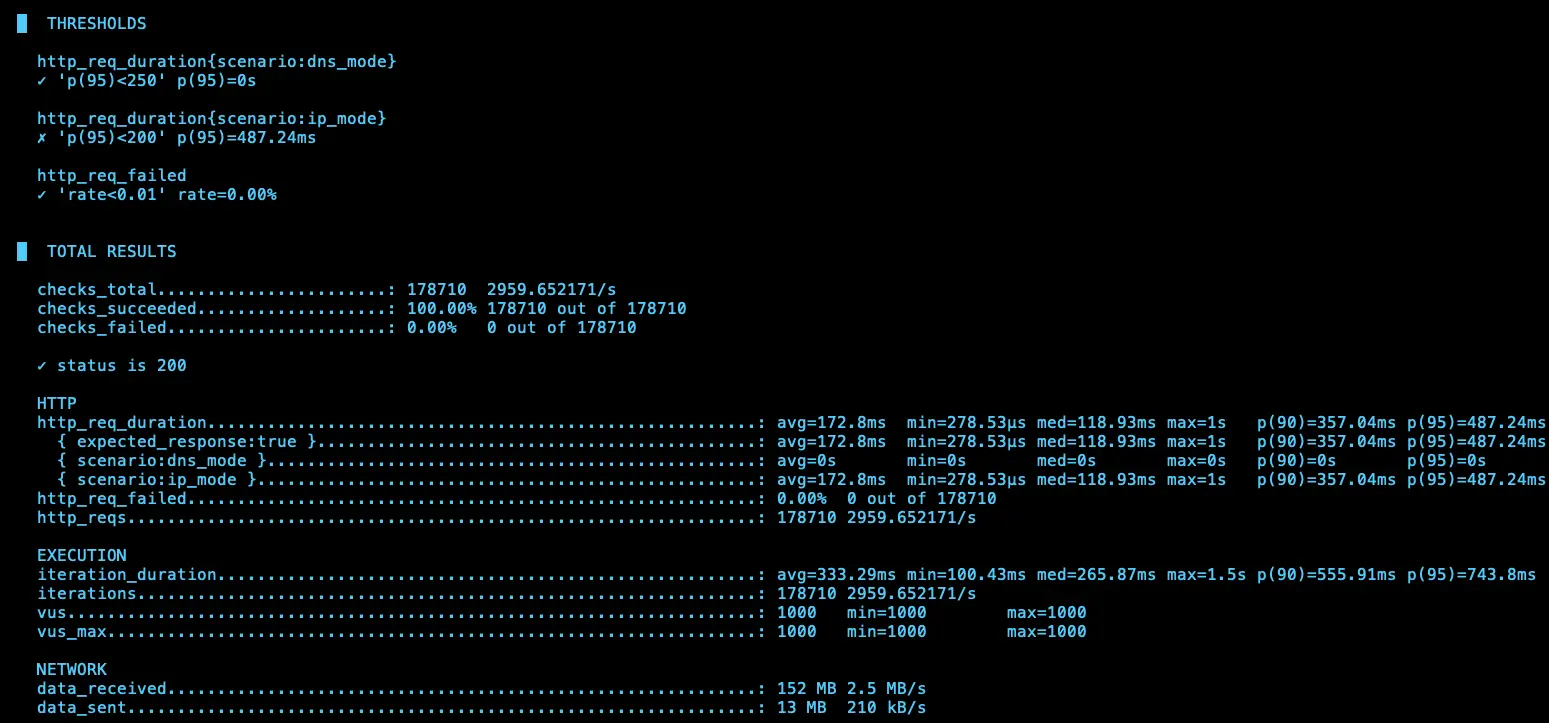
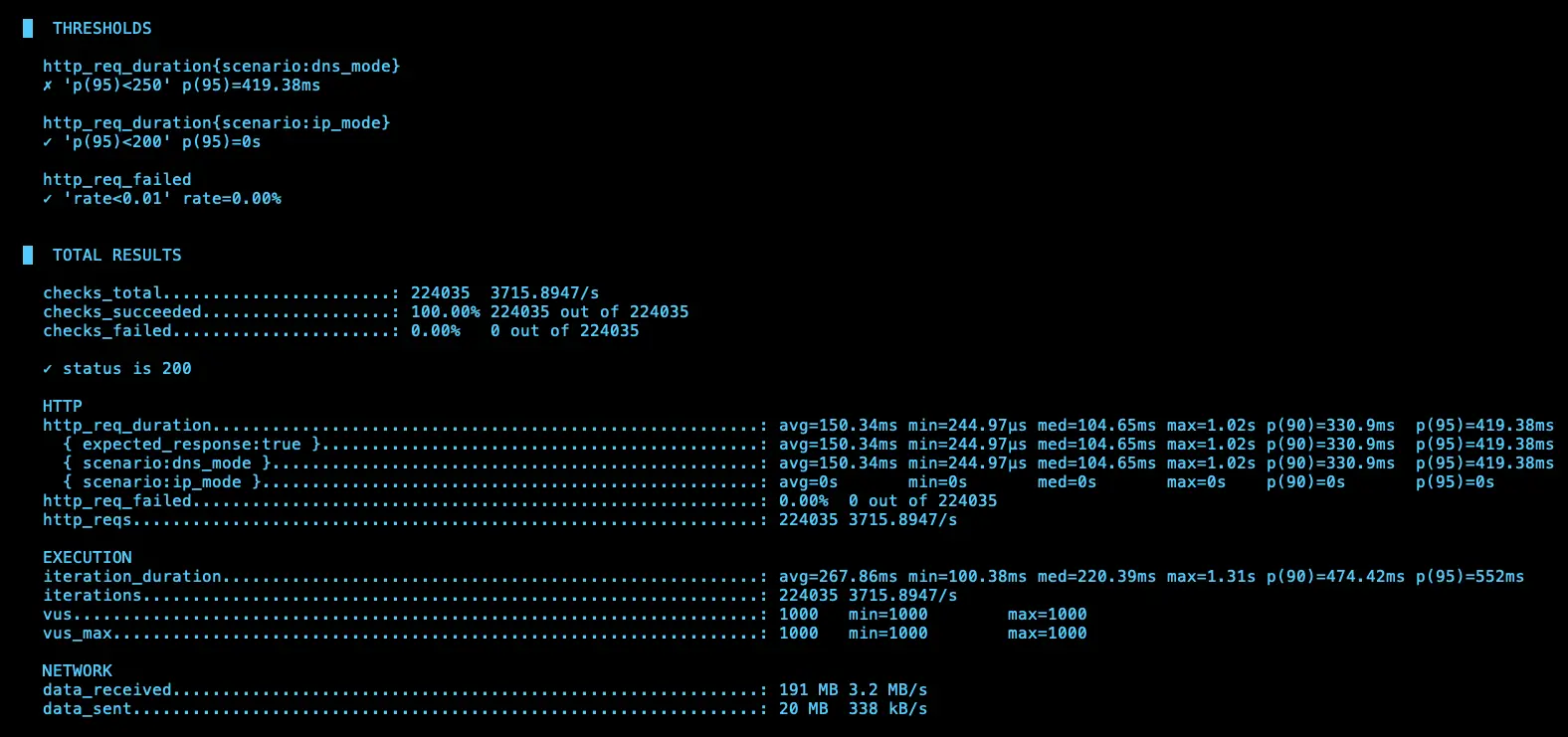
第四次測試
IP (avg=168.01ms / 3071 RPS)、DNS (avg=168.14ms / 3018 RPS)
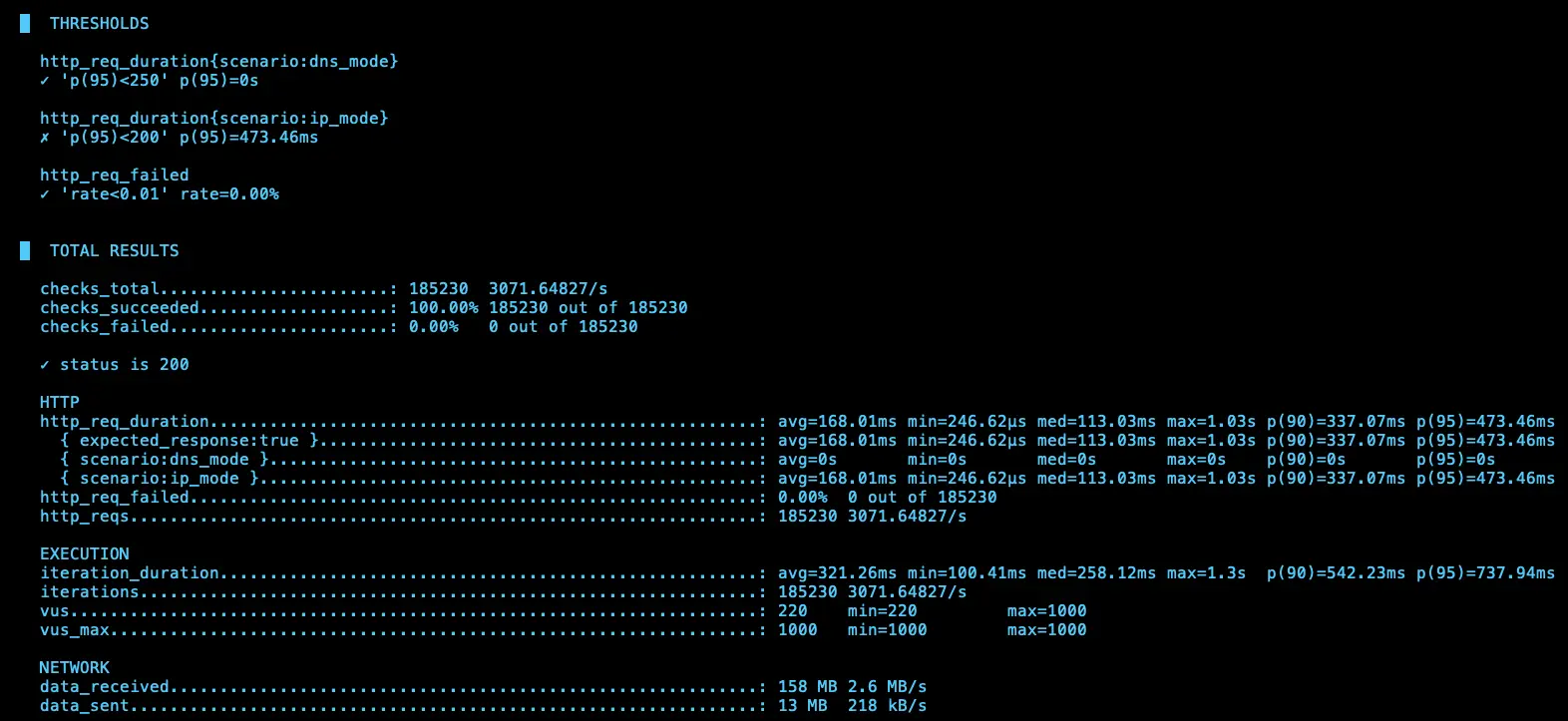
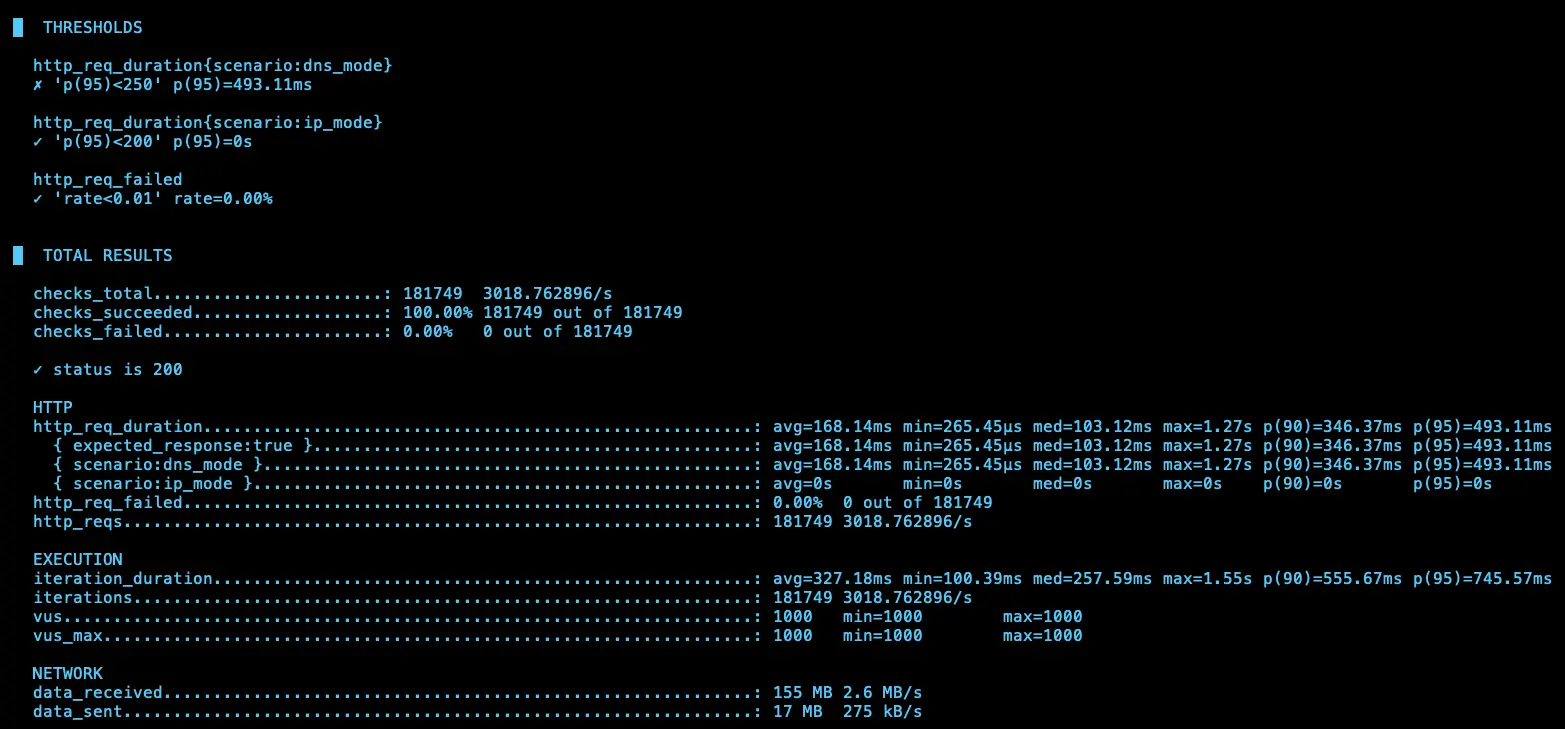
結論
理論上 ip 應該會比 dns 還要快,但測試 4 次發現其實不一定
結論
可以發現,使用 Cloud DNS + NodeLocal DNSCache 的模式下,不管是哪一個解析,不會使用到 KubeDNS,所以可以把 KubeDNS 關成 0 顆,避免浪費資源。
但是也可以發現當 NodeLocal DNSCache 只要發生問題,所有的解析都會有異常,所以不太建議使用 Cloud DNS + NodeLocal DNSCache 的模式
](/gcp/gke-cloud-dns-nodelocaldnscache/nodelocal-dnscache-cloud-dns.webp)
https://cloud.google.com/kubernetes-engine/docs/how-to/nodelocal-dns-cache?hl=zh-tw#cloud_dns_dataplane
由於官方流程圖有些細節沒有揭露的完成,我們有額外詢問 Google TAM,並畫出以下流程圖,Google TAM 也確認流程正確
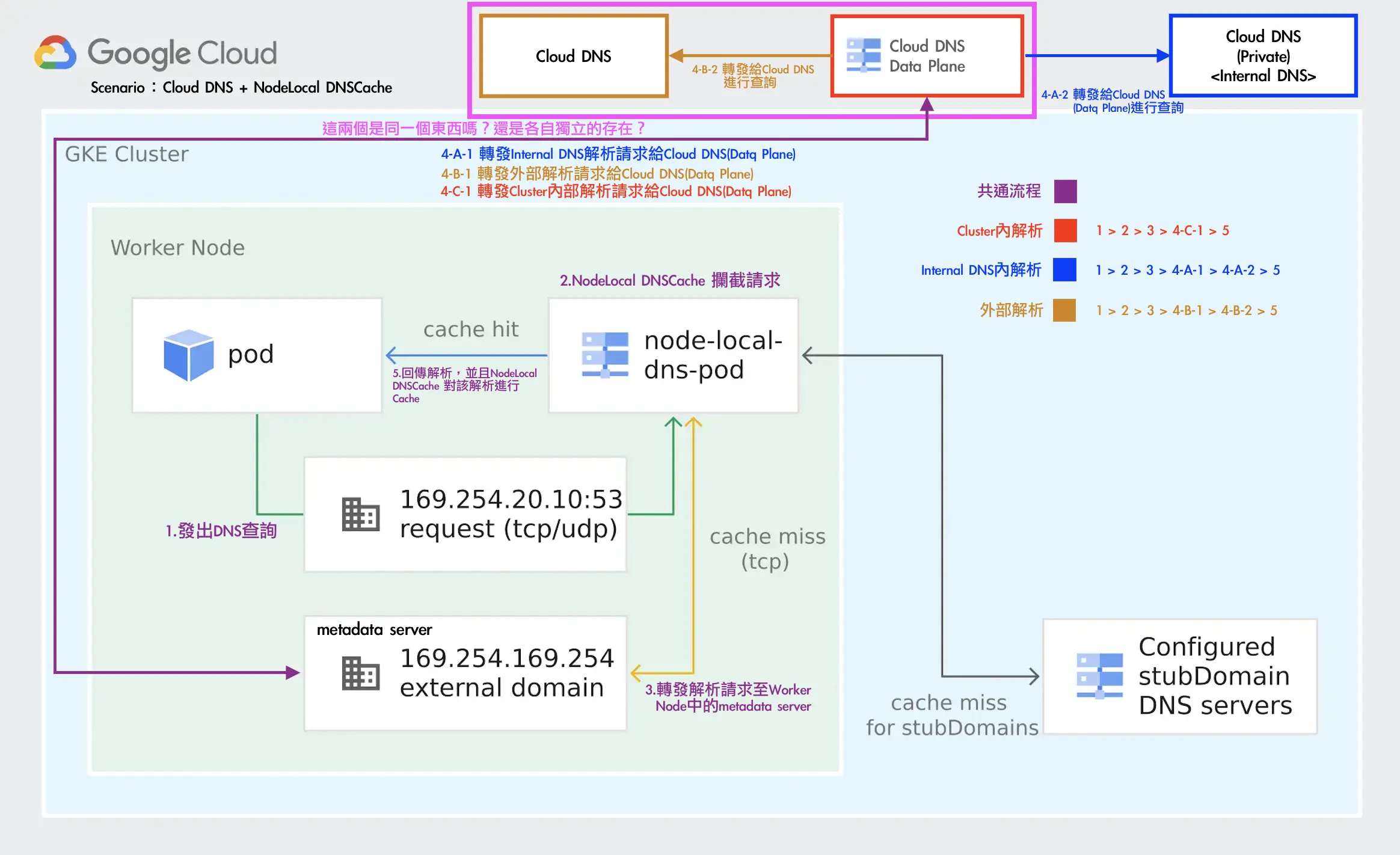
另外也可以從官方文件中得知 KubeDNS + NodeLocal DNSCache 的 /etc/resolv.conf 設定值,可以知道 Pod 最開始使用的 DNS 解析 Server 是誰。
](/gcp/gke-cloud-dns-nodelocaldnscache/resolv.webp)

參考資料
搭配 Cloud DNS 使用 NodeLocal DNSCache:https://cloud.google.com/kubernetes-engine/docs/how-to/nodelocal-dns-cache?hl=zh-tw#cloud_dns_dataplane