GKE DNS 使用 KubeDNS + NodeLocal DNSCache 運作測試
最近在評估要將公司內的 EndPoint 都改成 Cloud DNS 的 Private Zone (打造內部的 internal dns 服務機制),到時候 DNS 解析的請求會比以往還要多,所以需要先測試評估 GKE 內的 DNS 解析方案,避免再次發生 Pod 出現 cURL error 6: Could not resolve host,此篇文章測試的是: KubeDNS + NodeLocal DNSCache 的運作。
首先,先建立一個 dns-test pod 程式連結 以及 nginx 的 pod + svc 程式連結,會分別測試
叢集內部 cluster.local (nginx-svc.default.svc.cluster.local)
internal-dns 使用 cloud dns private (aaa.test-audit.com)
外部 dns (ifconfig.me)
並使用 nslookup 腳本進行確認回傳 DNS 解析,每一次測試都會重新建立 KubeDNS、NodeLocal DNSCache Pod
相關程式以及 Prometheus、Grafana 的設定可以參考:https://github.com/880831ian/gke-dns
叢集內部 cluster.local
NodeLocal DNSCache Prometheus 監控設定參數:zones="cluster.local."
- 相關 Prometheus 監控指標:
coredns_cache_requests_total{job="kubedns-nodelocaldns", zones="cluster.local."}
coredns_cache_entries{job="kubedns-nodelocaldns", zones="cluster.local."}
coredns_cache_hits_total{job="kubedns-nodelocaldns", zones="cluster.local."}
coredns_cache_misses_total{job="kubedns-nodelocaldns", zones="cluster.local."}
kubedns_dnsmasq_hits{job="kubedns-dns"}
kubedns_dnsmasq_misses{job="kubedns-dns"}測試腳本:
#!/bin/bash
get_taiwan_time() {
# 獲取當前 UTC 時間的 Unix 時間戳
UTC_TIMESTAMP=$(date -u +%s)
# 加上 8 小時 (台灣時間是 UTC+8)
TAIPEI_TIMESTAMP=$((UTC_TIMESTAMP + 28800))
# 將時間戳轉換為格式化後的日期時間
date -d "@$TAIPEI_TIMESTAMP" "+%Y-%m-%d %H:%M:%S"
}
DOMAIN="nginx-svc.default.svc.cluster.local"
EXPECTED_IP="10.36.16.35"
START_TIME=$(get_taiwan_time)
COUNT=10000
SUCCESS_COUNT=0
FAIL_COUNT=0
echo "== NSLOOKUP TEST START: $START_TIME ==" | tee -a nslookup_full.log
for i in $(seq 1 "$COUNT"); do
OUTPUT=$(nslookup "$DOMAIN" 2>&1)
ADDR_LINE=$(echo "$OUTPUT" | grep -E '^Address:')
if [[ "$ADDR_LINE" == *"$EXPECTED_IP"* ]]; then
SUCCESS_COUNT=$((SUCCESS_COUNT + 1))
else
FAIL_COUNT=$((FAIL_COUNT + 1))
fi
echo "[$i] === $(get_taiwan_time) 成功: $SUCCESS_COUNT 失敗: $FAIL_COUNT"
done
END_TIME=$(get_taiwan_time)
echo "== NSLOOKUP TEST END: $END_TIME ==" | tee -a nslookup_full.log
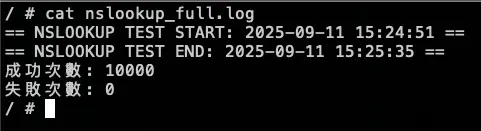
echo "成功次數: $SUCCESS_COUNT" | tee -a nslookup_full.log
echo "失敗次數: $FAIL_COUNT" | tee -a nslookup_full.log10.36.16.35 是 nginx-svc Cluster IP
需要先確認 nginx-svc 的 IP 是多少,然後修改腳本中的 EXPECTED_IP 變數。
測試腳本
測試結果:
結論
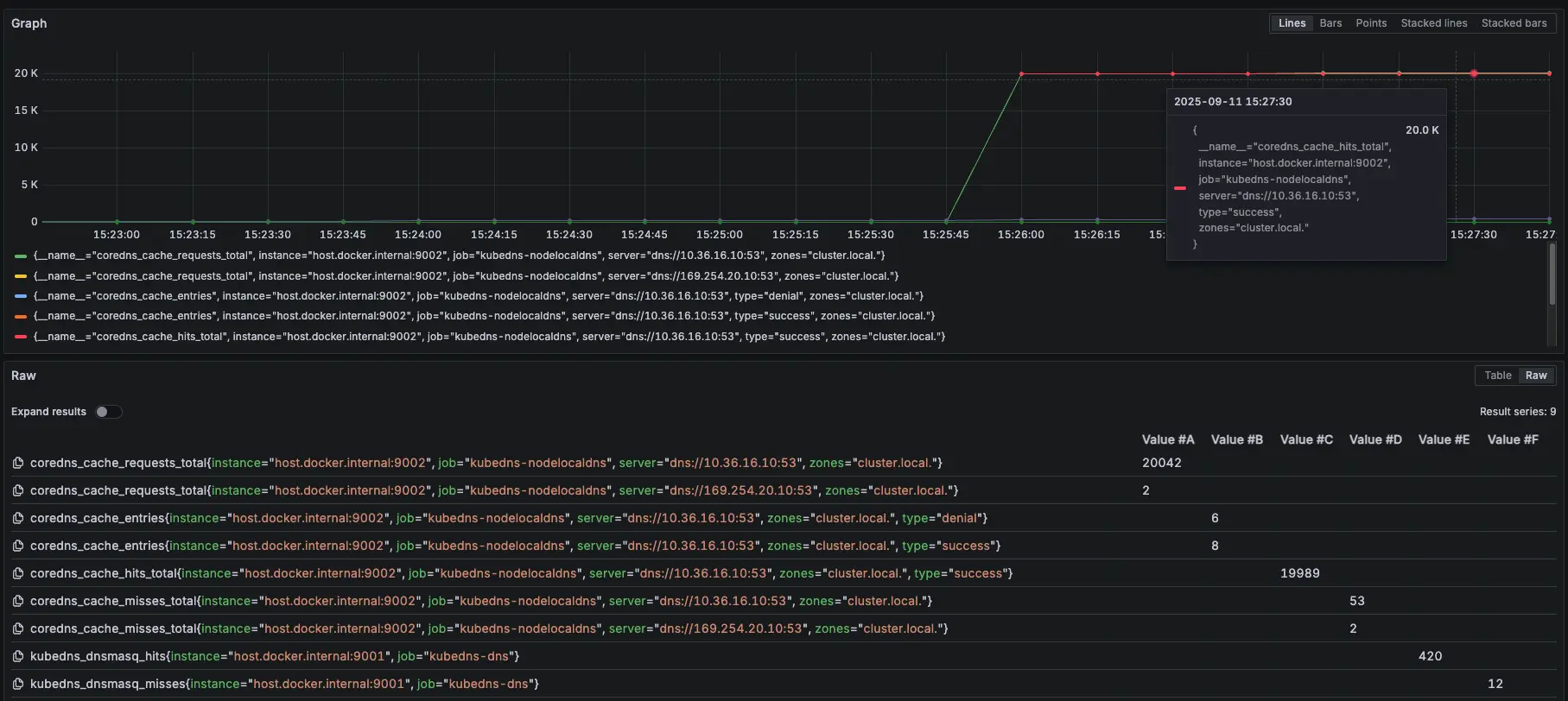
可以觀察 NodeLocal DNSCache 內的指標 hit 跟 request 都有持續上升
模擬 KubeDNS Pod 異常
接下來會在測試中,將 KubeDNS 調整到 0 顆,再開回去,觀察此模式對於 KubeDNS 的依賴
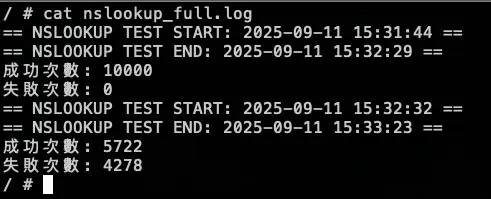
測試結果:

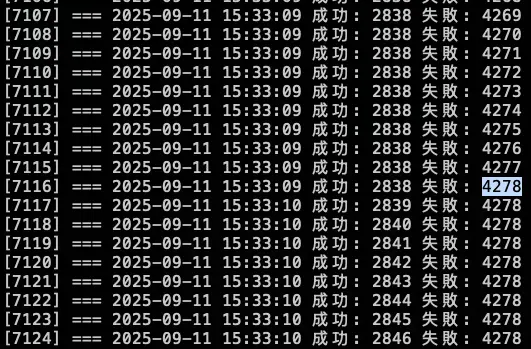
結論
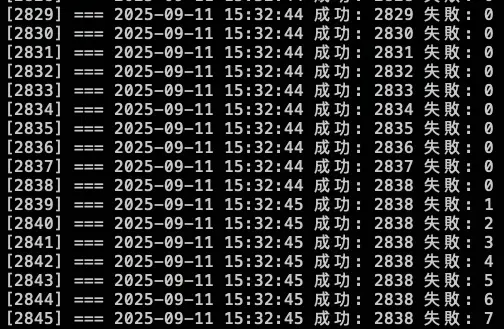
總共打了兩輪的 10000 筆,在第一輪大約在 2000 筆請求時左右將 KubeDNS 關成 0 顆,但到了第二輪的 2838 筆的時候才開始出現解析失敗,因為前面 KubeDNS 切成 0,Pod 不會馬上關掉,所以還能夠解析 DNS,中間又因爲有 NodeLocal DNSCache 做 Cache,所以 DNS 解析還有相關紀錄可以回覆,但後面當 Cache TTL 到期後,需要先訪問 KubeDNS 時,此時 KubeDNS 也已經關閉,最後才會出現解析錯誤
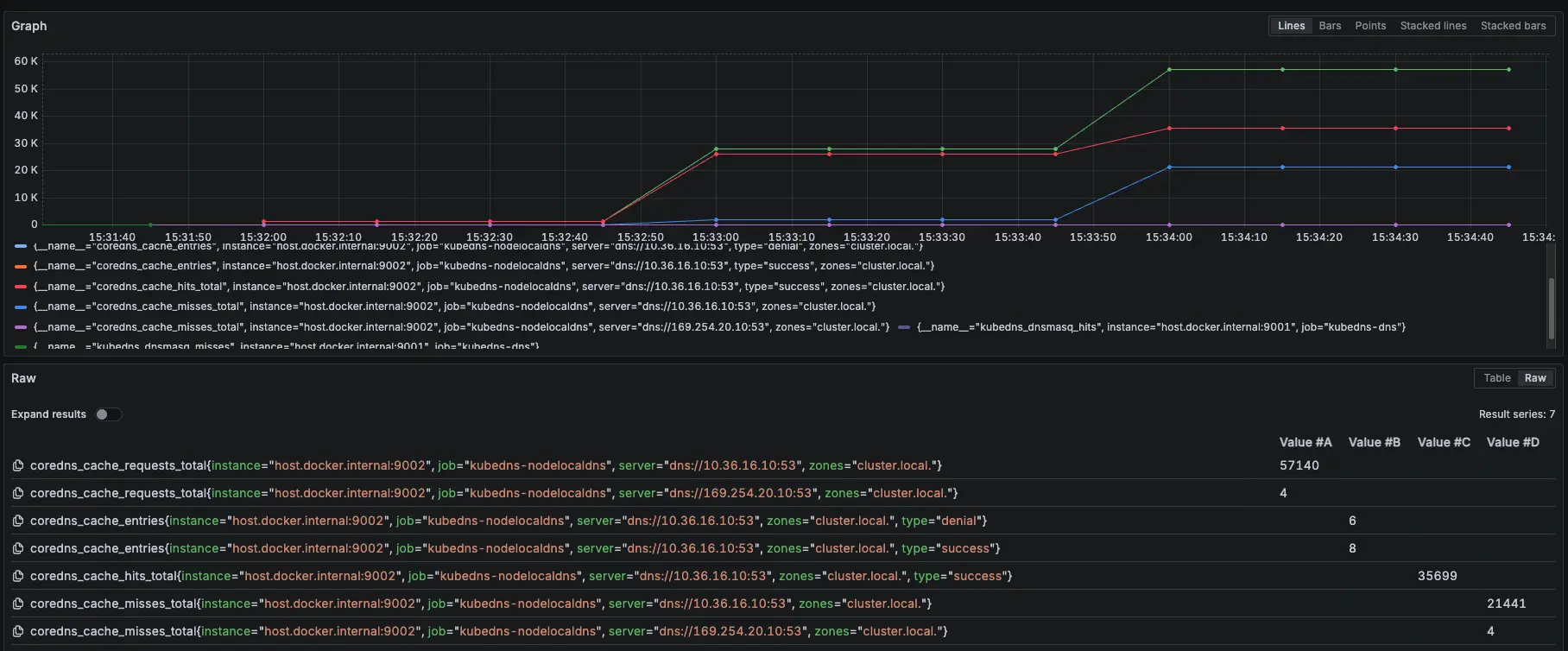
從 Prometheus 可以發現,前面 NodeLocal DNSCache request 跟 hit 差不多,但當 15:33 線圖開始 request 大於 hit,且出現 miss,這代表因為後面的 KubeDNS 異常,導致 NodeLocal DNSCache 沒辦法做 Cache hit
模擬 NodeLocal DNSCache Pod 異常
接下來我們測試最後一個情境,故意用壞 NodeLocal DNSCache 服務,觀察此模式對於 NodeLocal DNSCache 的依賴
測試情境:
先調整 COUNT 參數變成 50000
先跑 15000 筆有 NodeLocal DNSCache,然後使用以下指令讓 NodeLocal DNSCache 無法使用
kubectl patch daemonset node-local-dns -n kube-system --type='strategic' -p '{"spec":{"template":{"spec":{"nodeSelector":{"this-label-does-not-exist-on-any-node":"true"}}}}}'等待約 30000 筆時,使用以下指令恢復 NodeLocal DNSCache
kubectl patch daemonset node-local-dns -n kube-system --type='strategic' -p '{"spec":{"template":{"spec":{"nodeSelector":null}}}}'測試結果:
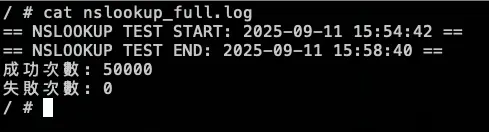
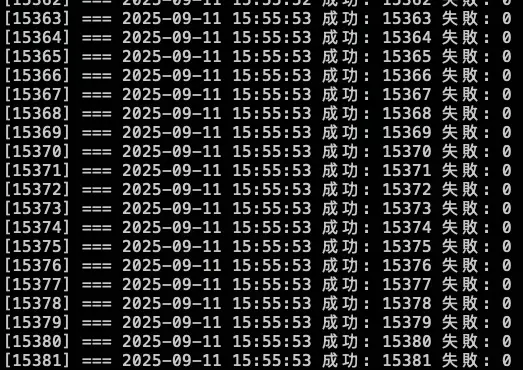
分別在 15:55:53 跟 15:57:04 下指令調整

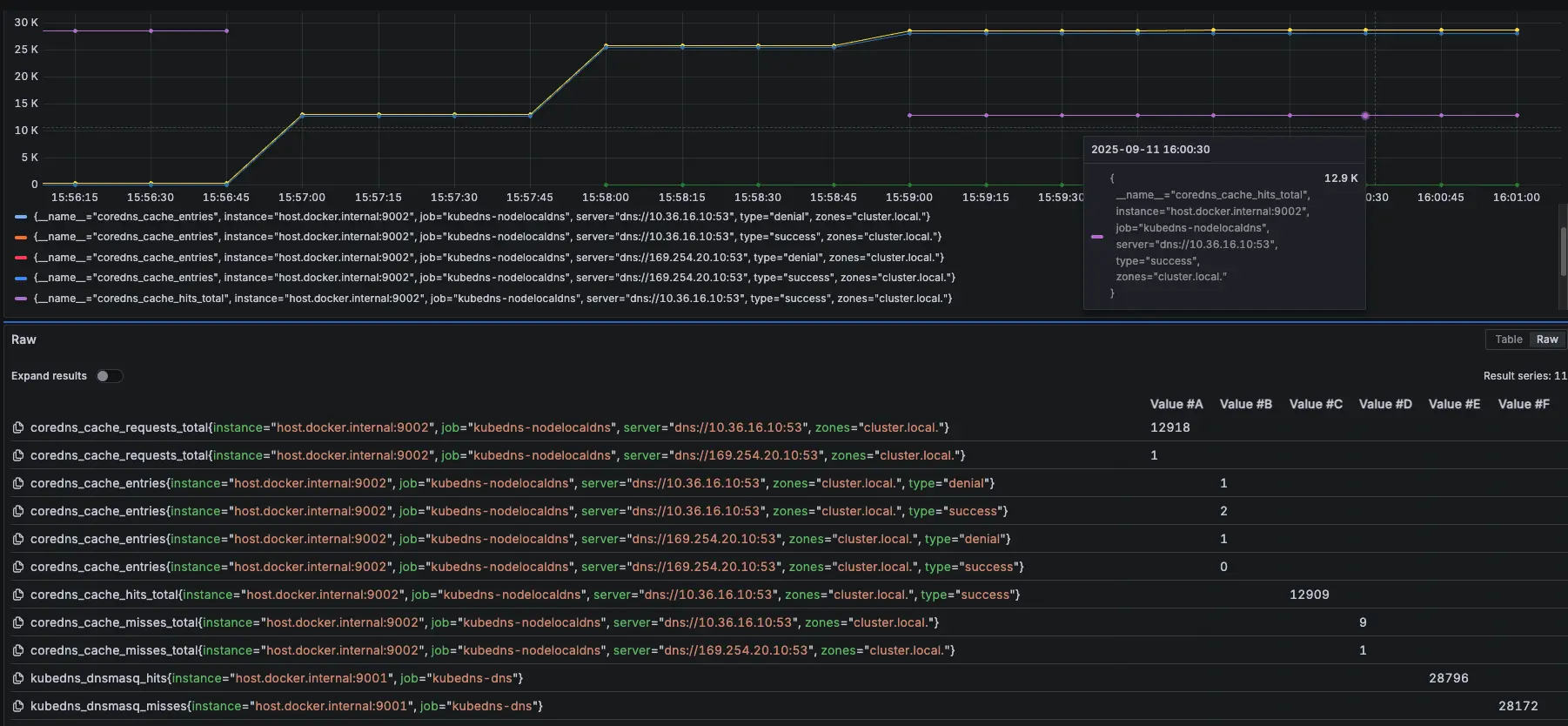
結論
發現當 NodeLocal DNSCache 掛了後,會短暫卡住,但會直接切換到 KubeDNS 上繼續進行解析,因此以結果論,如果 NodeLocal DNSCache 有短暫異常,不會出現無法解析的問題
從 Prometheus 可以發現,前面 NodeLocal DNSCache 正常運作,當我們在 15:55:53 調整後,變成 KubeDNS 起來開始處理解析,在 15:57:04 切換讓 NodeLocal DNSCache 恢復,後面又會變成由 NodeLocal DNSCache 來處理解析
紫色是 NodeLocal DNSCache,黃色是 KubeDNS
Internal DNS (Cloud DNS Private)
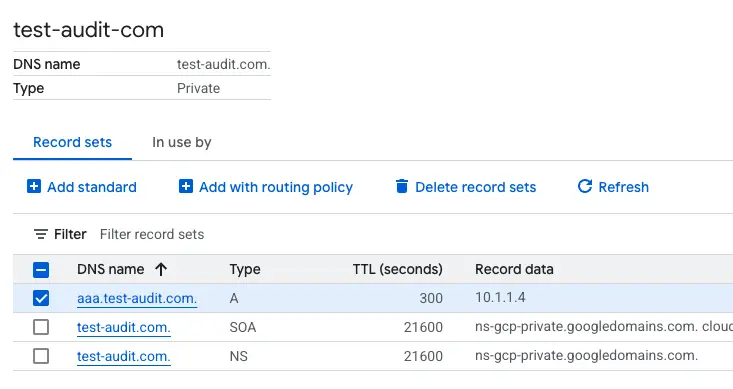
先建立一個 cloud dns private,以下範例是 aaa.test-audit.com > 10.1.1.4,並將此 use VPC 與 GKE 的 VPC 打通
NodeLocal DNSCache Prometheus 監控設定參數:zones="."
- 相關 Prometheus 監控指標:
coredns_cache_requests_total{job="kubedns-nodelocaldns", zones="."}
coredns_cache_entries{job="kubedns-nodelocaldns", zones="."}
coredns_cache_hits_total{job="kubedns-nodelocaldns", zones="."}
coredns_cache_misses_total{job="kubedns-nodelocaldns", zones="."}
kubedns_dnsmasq_hits{job="kubedns-dns"}
kubedns_dnsmasq_misses{job="kubedns-dns"}測試腳本:
#!/bin/bash
get_taiwan_time() {
# 獲取當前 UTC 時間的 Unix 時間戳
UTC_TIMESTAMP=$(date -u +%s)
# 加上 8 小時 (台灣時間是 UTC+8)
TAIPEI_TIMESTAMP=$((UTC_TIMESTAMP + 28800))
# 將時間戳轉換為格式化後的日期時間
date -d "@$TAIPEI_TIMESTAMP" "+%Y-%m-%d %H:%M:%S"
}
DOMAIN="aaa.test-audit.com"
EXPECTED_IP="10.1.1.4"
START_TIME=$(get_taiwan_time)
COUNT=10000
SUCCESS_COUNT=0
FAIL_COUNT=0
echo "== NSLOOKUP TEST START: $START_TIME ==" | tee -a nslookup_full.log
for i in $(seq 1 "$COUNT"); do
OUTPUT=$(nslookup "$DOMAIN" 2>&1)
ADDR_LINE=$(echo "$OUTPUT" | grep -E '^Address:')
if [[ "$ADDR_LINE" == *"$EXPECTED_IP"* ]]; then
SUCCESS_COUNT=$((SUCCESS_COUNT + 1))
else
FAIL_COUNT=$((FAIL_COUNT + 1))
fi
echo "[$i] === $(get_taiwan_time) 成功: $SUCCESS_COUNT 失敗: $FAIL_COUNT"
done
END_TIME=$(get_taiwan_time)
echo "== NSLOOKUP TEST END: $END_TIME ==" | tee -a nslookup_full.log
echo "成功次數: $SUCCESS_COUNT" | tee -a nslookup_full.log
echo "失敗次數: $FAIL_COUNT" | tee -a nslookup_full.log10.1.1.4 是隨機亂取的 IP,只是為了確認 domain 是否能夠正常解析
測試腳本
測試結果:
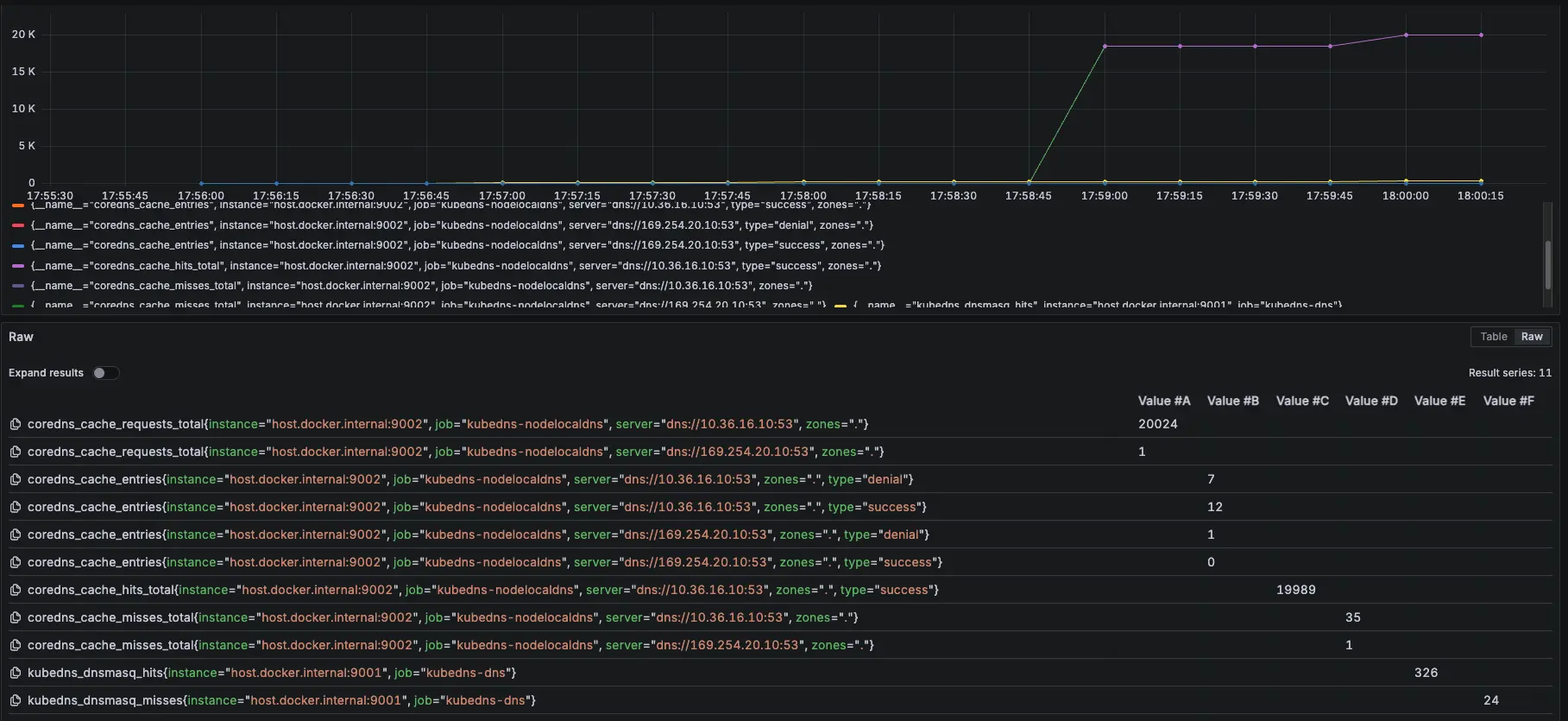
結論
可以觀察 NodeLocal DNSCache 內的指標 hit 跟 request 都有持續上升
模擬 KubeDNS Pod 異常
接下來會在測試中,將 KubeDNS 調整到 0 顆,再開回去,觀察此模式對於 KubeDNS 的依賴
測試結果:
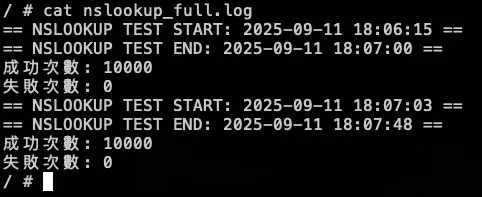

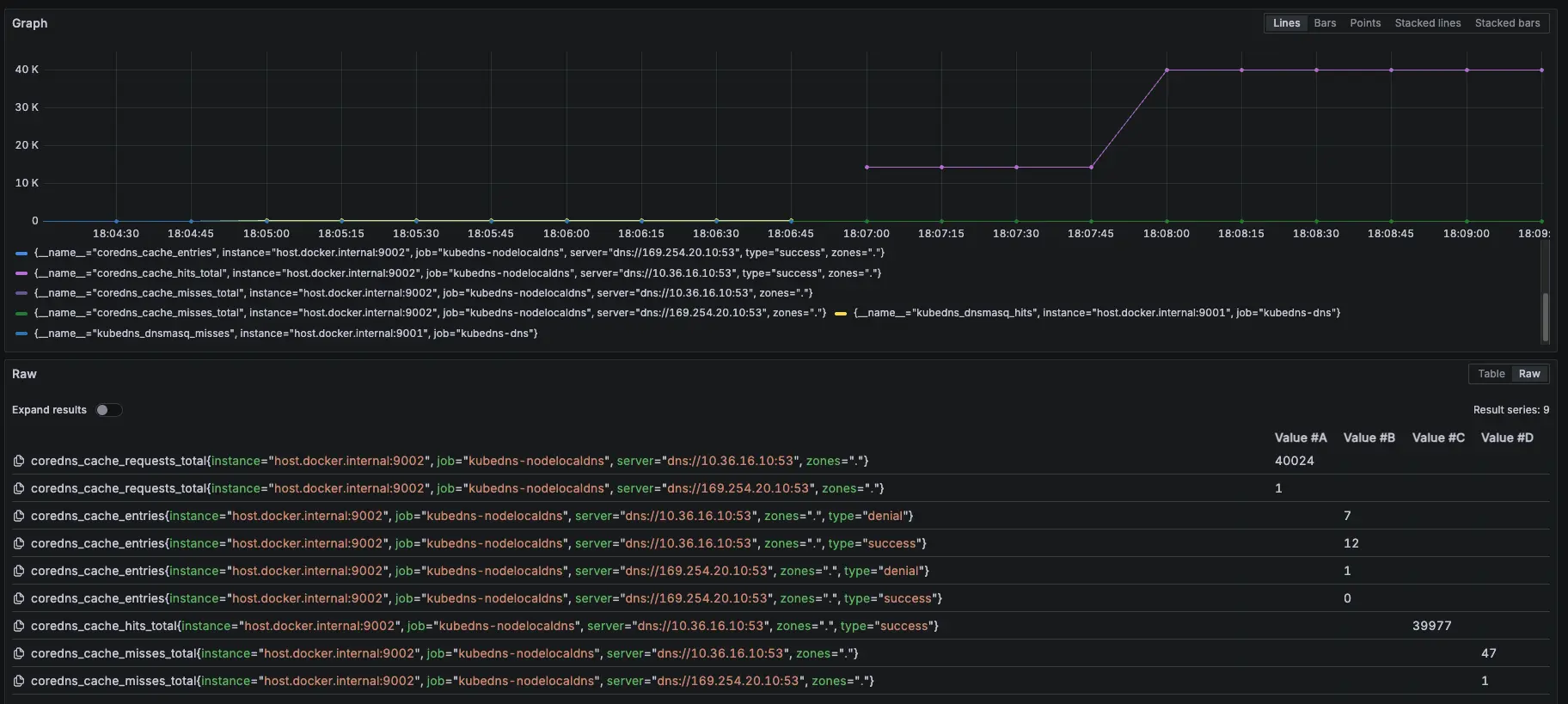
結論
總共打了兩輪的 10000 筆,在第一輪大約在 2000 筆請求時左右將 KubeDNS 關成 0 顆,因為前面 KubeDNS 切成 0,Pod 不會馬上關掉,避免有測試誤差,所以在打第二輪 10000 筆,但從結果發現,所有的 DNS 請求都是走 NodeLocal DNSCache,因為 cloud dns private 不是 .cluster.local,所以就算沒有 KubeDNS 也能正常運作
模擬 NodeLocal DNSCache Pod 異常
接下來我們測試最後一個情境,故意用壞 NodeLocal DNSCache 服務,觀察此模式對於 NodeLocal DNSCache 的依賴
測試情境:
先調整 COUNT 參數變成 50000
先跑 15000 筆有 NodeLocal DNSCache,然後使用以下指令讓 NodeLocal DNSCache 無法使用
kubectl patch daemonset node-local-dns -n kube-system --type='strategic' -p '{"spec":{"template":{"spec":{"nodeSelector":{"this-label-does-not-exist-on-any-node":"true"}}}}}'等待約 30000 筆時,使用以下指令恢復 NodeLocal DNSCache
kubectl patch daemonset node-local-dns -n kube-system --type='strategic' -p '{"spec":{"template":{"spec":{"nodeSelector":null}}}}'測試結果:
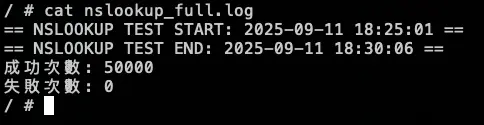
分別在 18:26:11 跟 18:28:03 下指令調整

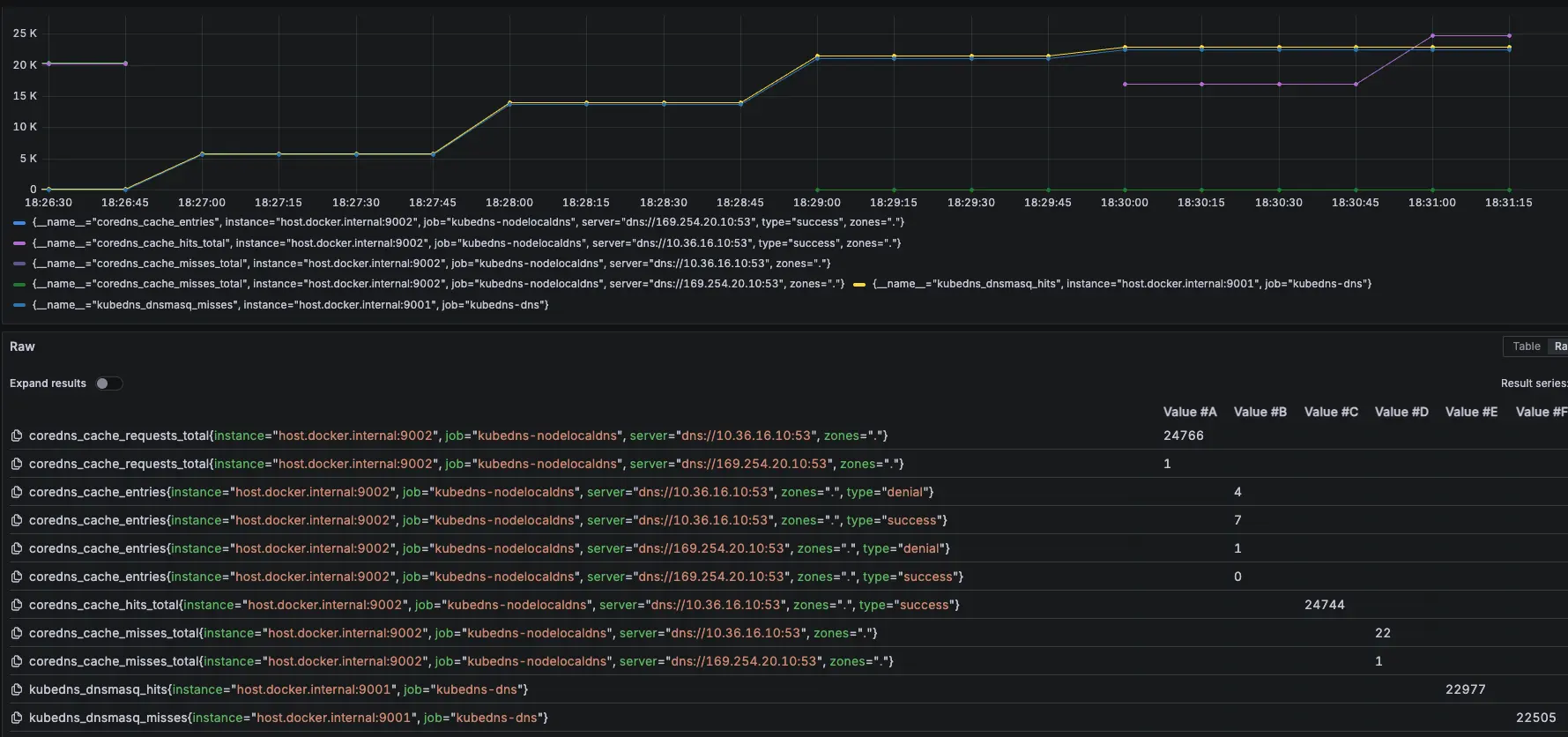
結論
發現當 NodeLocal DNSCache 掛了後,會短暫卡住,但會直接切換到 KubeDNS 上繼續進行解析,因此以結果論,如果 NodeLocal DNSCache 有短暫異常,不會出現無法解析的問題
從 Prometheus 可以發現,前面 NodeLocal DNSCache 正常運作,當我們在 18:26:11 調整後,變成 KubeDNS 起來開始處理解析,在 18:28:03 切換讓 NodeLocal DNSCache 恢復,後面又會變成由 NodeLocal DNSCache 來處理解析
紫色是 NodeLocal DNSCache,黃色是 KubeDNS
外部 DNS (ifconfig.me)
NodeLocal DNSCache Prometheus 監控設定參數:zones="."
- 相關 Prometheus 監控指標:
coredns_cache_requests_total{job="kubedns-nodelocaldns", zones="."}
coredns_cache_entries{job="kubedns-nodelocaldns", zones="."}
coredns_cache_hits_total{job="kubedns-nodelocaldns", zones="."}
coredns_cache_misses_total{job="kubedns-nodelocaldns", zones="."}
kubedns_dnsmasq_hits{job="kubedns-dns"}
kubedns_dnsmasq_misses{job="kubedns-dns"}測試腳本:
#!/bin/bash
get_taiwan_time() {
# 獲取當前 UTC 時間的 Unix 時間戳
UTC_TIMESTAMP=$(date -u +%s)
# 加上 8 小時 (台灣時間是 UTC+8)
TAIPEI_TIMESTAMP=$((UTC_TIMESTAMP + 28800))
# 將時間戳轉換為格式化後的日期時間
date -d "@$TAIPEI_TIMESTAMP" "+%Y-%m-%d %H:%M:%S"
}
DOMAIN="ifconfig.me"
EXPECTED_IP="34.160.111.145"
START_TIME=$(get_taiwan_time)
COUNT=10000
SUCCESS_COUNT=0
FAIL_COUNT=0
echo "== NSLOOKUP TEST START: $START_TIME ==" | tee -a nslookup_full.log
for i in $(seq 1 "$COUNT"); do
OUTPUT=$(nslookup "$DOMAIN" 2>&1)
ADDR_LINE=$(echo "$OUTPUT" | grep -E '^Address:')
if [[ "$ADDR_LINE" == *"$EXPECTED_IP"* ]]; then
SUCCESS_COUNT=$((SUCCESS_COUNT + 1))
else
FAIL_COUNT=$((FAIL_COUNT + 1))
fi
echo "[$i] === $(get_taiwan_time) 成功: $SUCCESS_COUNT 失敗: $FAIL_COUNT"
done
END_TIME=$(get_taiwan_time)
echo "== NSLOOKUP TEST END: $END_TIME ==" | tee -a nslookup_full.log
echo "成功次數: $SUCCESS_COUNT" | tee -a nslookup_full.log
echo "失敗次數: $FAIL_COUNT" | tee -a nslookup_full.log34.160.111.145 是 ifconfig.me 的 IP,只是為了確認 domain 是否能夠正常解析
測試腳本
測試結果:
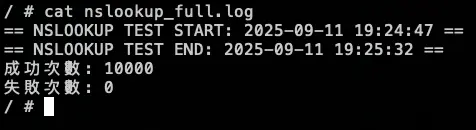
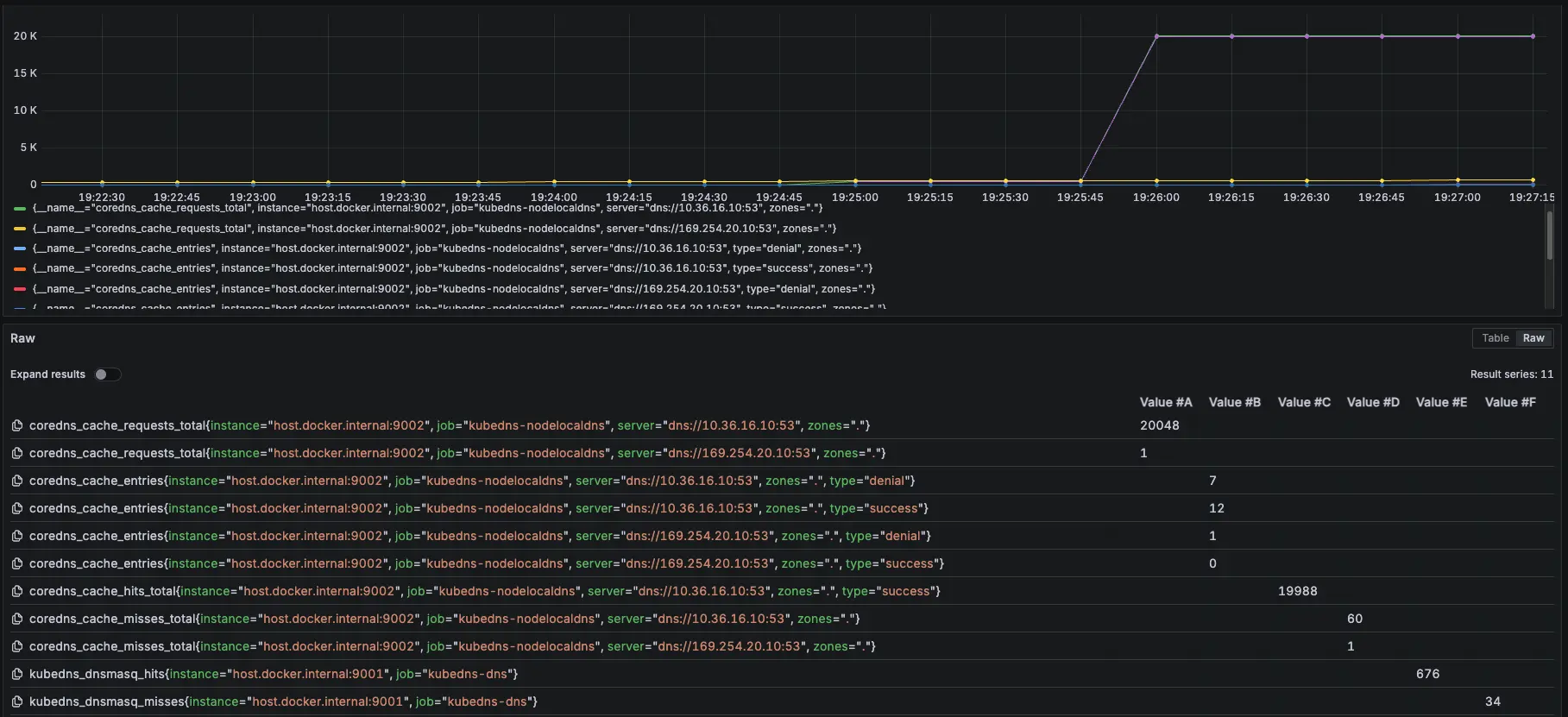
結論
可以觀察 NodeLocal DNSCache 內的指標 hit 跟 request 都有持續上升
模擬 KubeDNS Pod 異常
接下來會在測試中,將 KubeDNS 調整到 0 顆,再開回去,觀察此模式對於 KubeDNS 的依賴
測試結果:
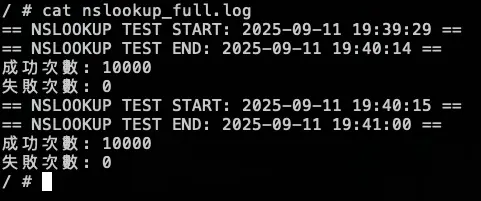

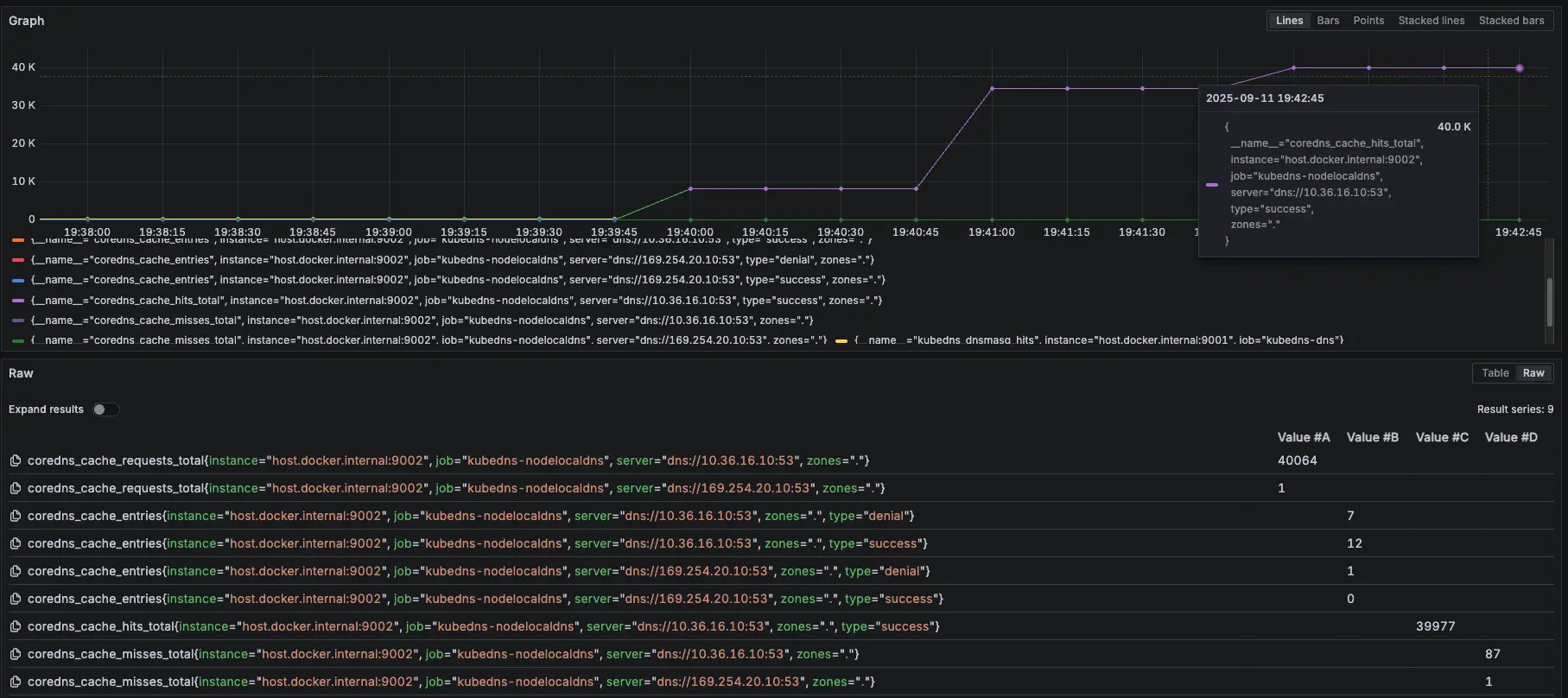
結論
總共打了兩輪的 10000 筆,在第一輪大約在 2000 筆請求時左右將 KubeDNS 關成 0 顆,因為前面 KubeDNS 切成 0,Pod 不會馬上關掉,避免有測試誤差,所以在打第二輪 10000 筆,但從結果發現,所有的 DNS 請求都是走 NodeLocal DNSCache,因為外部 dns 不是 .cluster.local,所以就算沒有 KubeDNS 也能正常運作
模擬 NodeLocal DNSCache Pod 異常
接下來我們測試最後一個情境,故意用壞 NodeLocal DNSCache 服務,觀察此模式對於 NodeLocal DNSCache 的依賴
測試情境:
先調整 COUNT 參數變成 50000
先跑 15000 筆有 NodeLocal DNSCache,然後使用以下指令讓 NodeLocal DNSCache 無法使用
kubectl patch daemonset node-local-dns -n kube-system --type='strategic' -p '{"spec":{"template":{"spec":{"nodeSelector":{"this-label-does-not-exist-on-any-node":"true"}}}}}'等待約 30000 筆時,使用以下指令恢復 NodeLocal DNSCache
kubectl patch daemonset node-local-dns -n kube-system --type='strategic' -p '{"spec":{"template":{"spec":{"nodeSelector":null}}}}'測試結果:
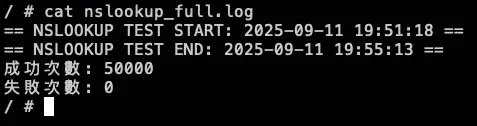
分別在 19:52:28 跟 19:53:16 下指令調整

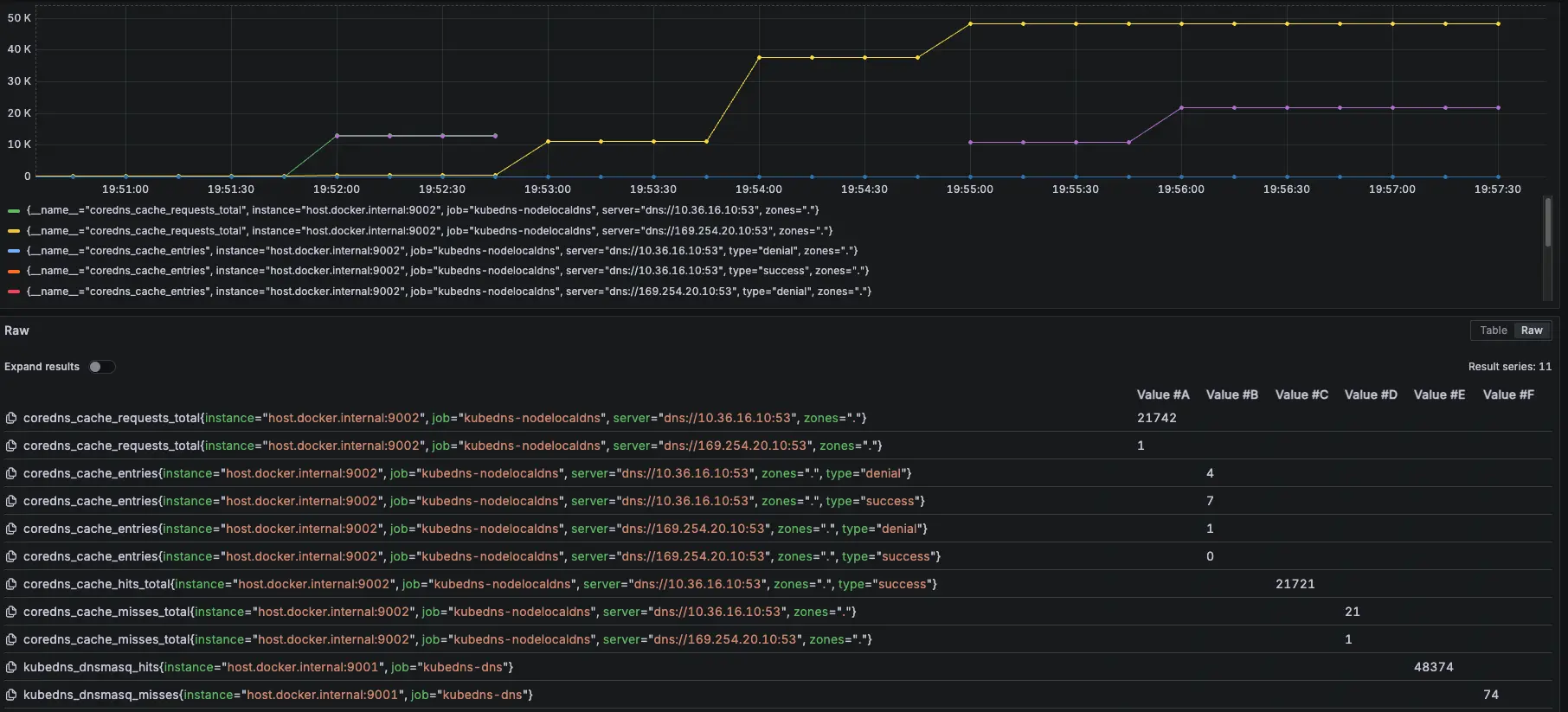
結論
發現當 NodeLocal DNSCache 掛了後,會短暫卡住,但會直接切換到 KubeDNS 上繼續進行解析,因此以結果論,如果 NodeLocal DNSCache 有短暫異常,不會出現無法解析的問題
從 Prometheus 可以發現,前面 NodeLocal DNSCache 正常運作,當我們在 19:52:28 調整後,變成 KubeDNS 起來開始處理解析,在 19:53:16 切換讓 NodeLocal DNSCache 恢復,後面又會變成由 NodeLocal DNSCache 來處理解析
紫色是 NodeLocal DNSCache,黃色是 KubeDNS
k6 測試
額外在另一個 cluster 建立 nginx deployment 開 5 個 pod 以及 svc 改成 lb (L4),然後在 cloud dns 的 test-audit-com 設定 nginx-lb-internal.test-audit.com 解析到內網的 svc (10.156.17.230)
使用 k6 測試 KubeDNS + NodeLocal DNSCache 模式下 IP 跟 DNS 的差異
相關程式可以參考:https://github.com/880831ian/gke-dns
這邊測試的 Node 是用 e2-medium 而非 c3d-standard-4
第一次測試
IP (avg=181.7ms / 3511 RPS)、DNS (avg=335.43ms / 2278 RPS)
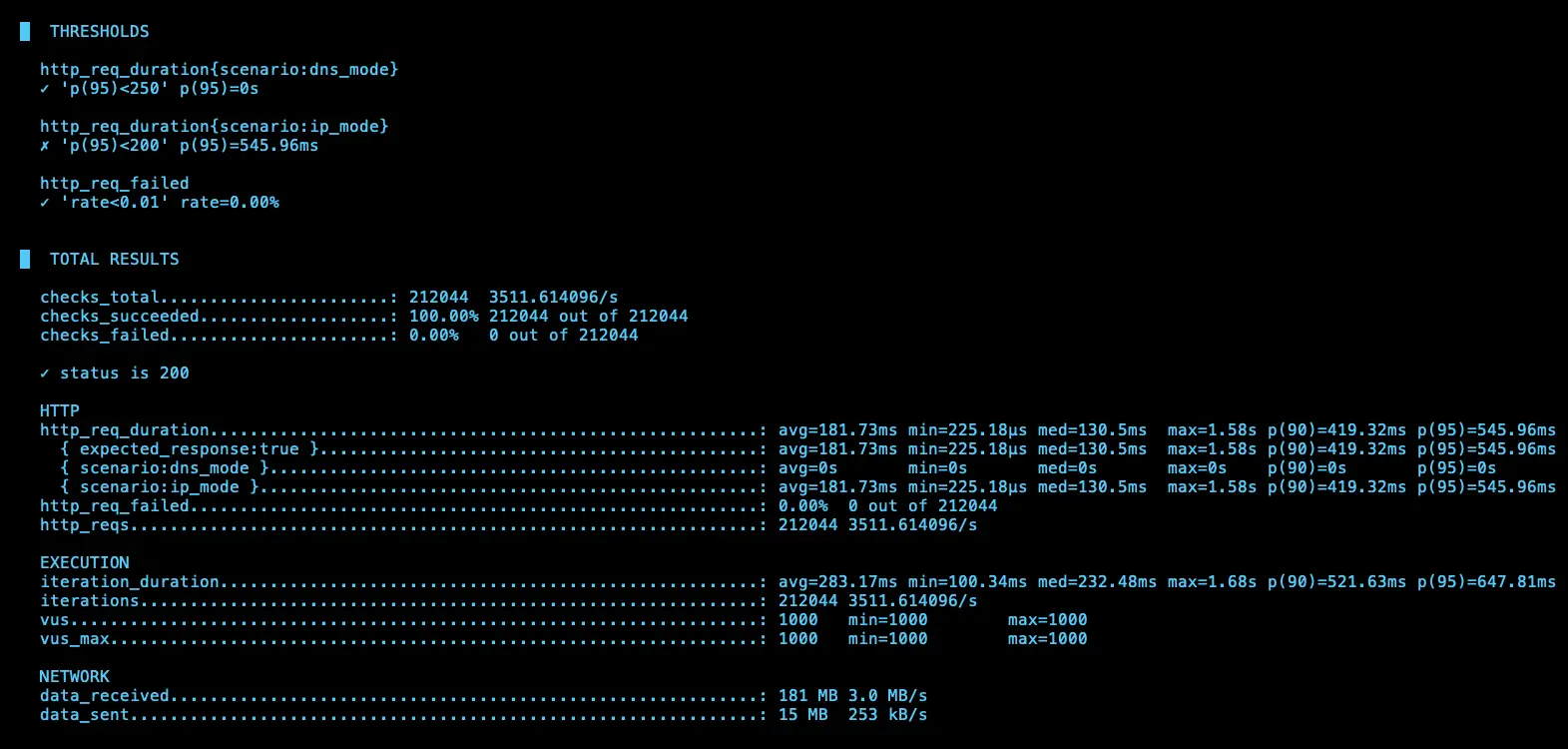
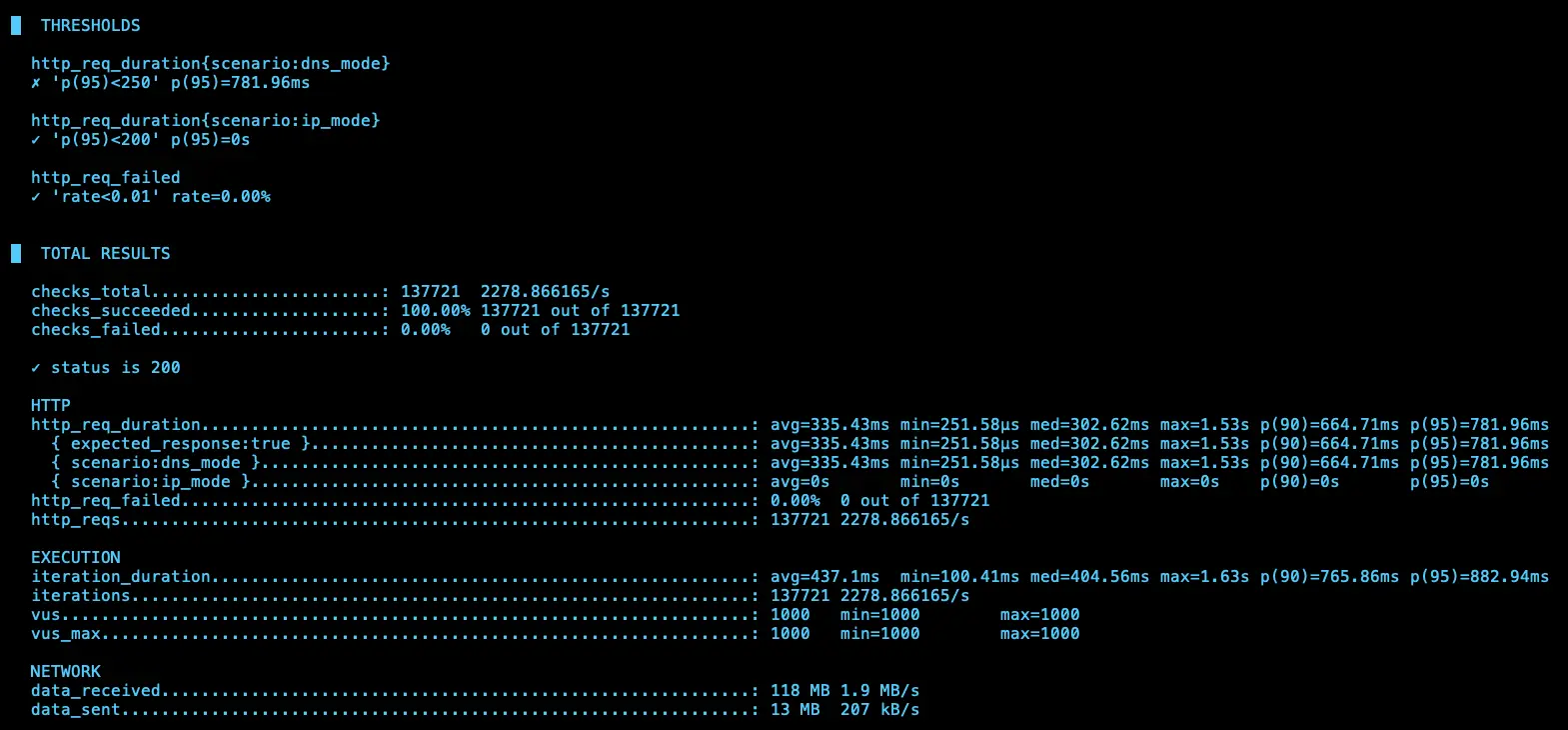
第二次測試
IP (avg=336.98ms / 2272 RPS)、DNS (avg=503.79ms / 1640 RPS)
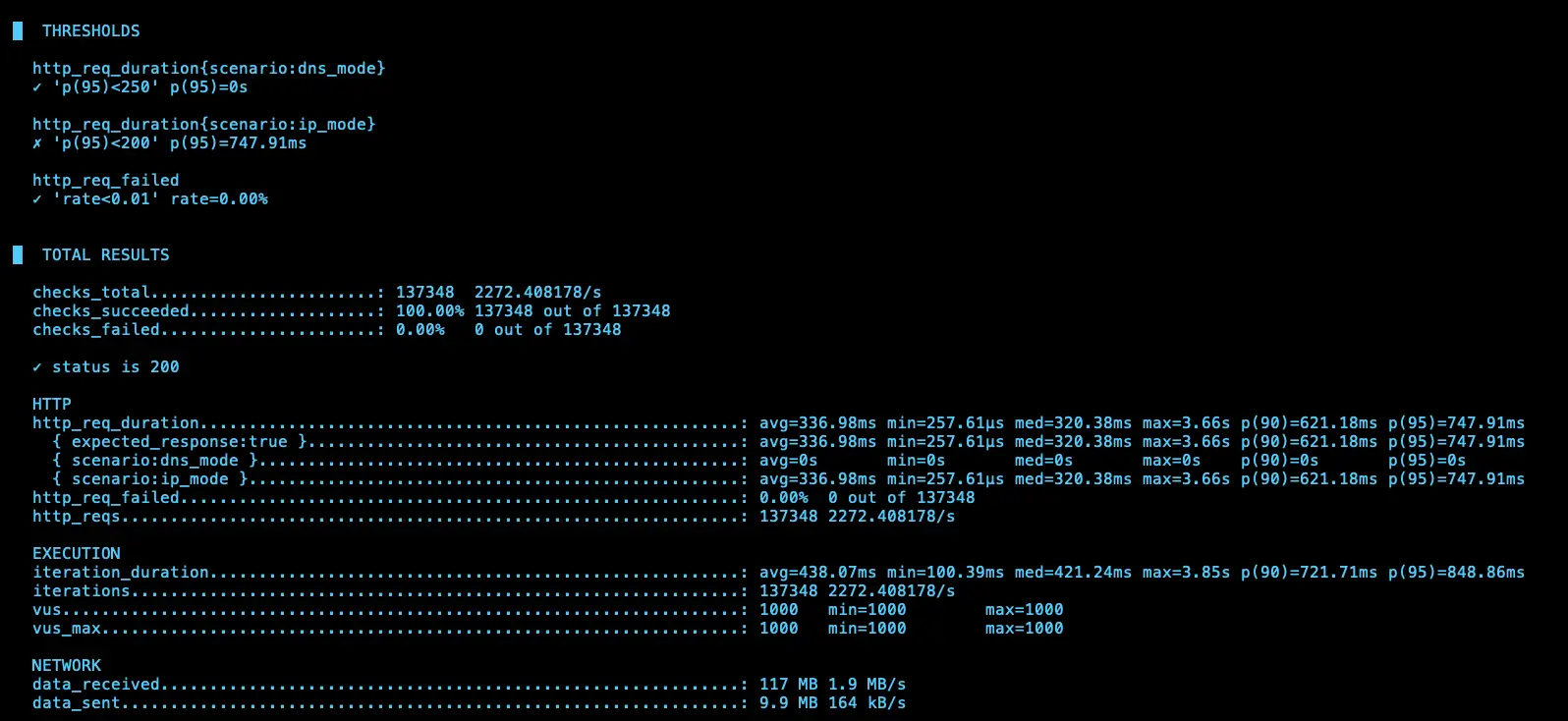
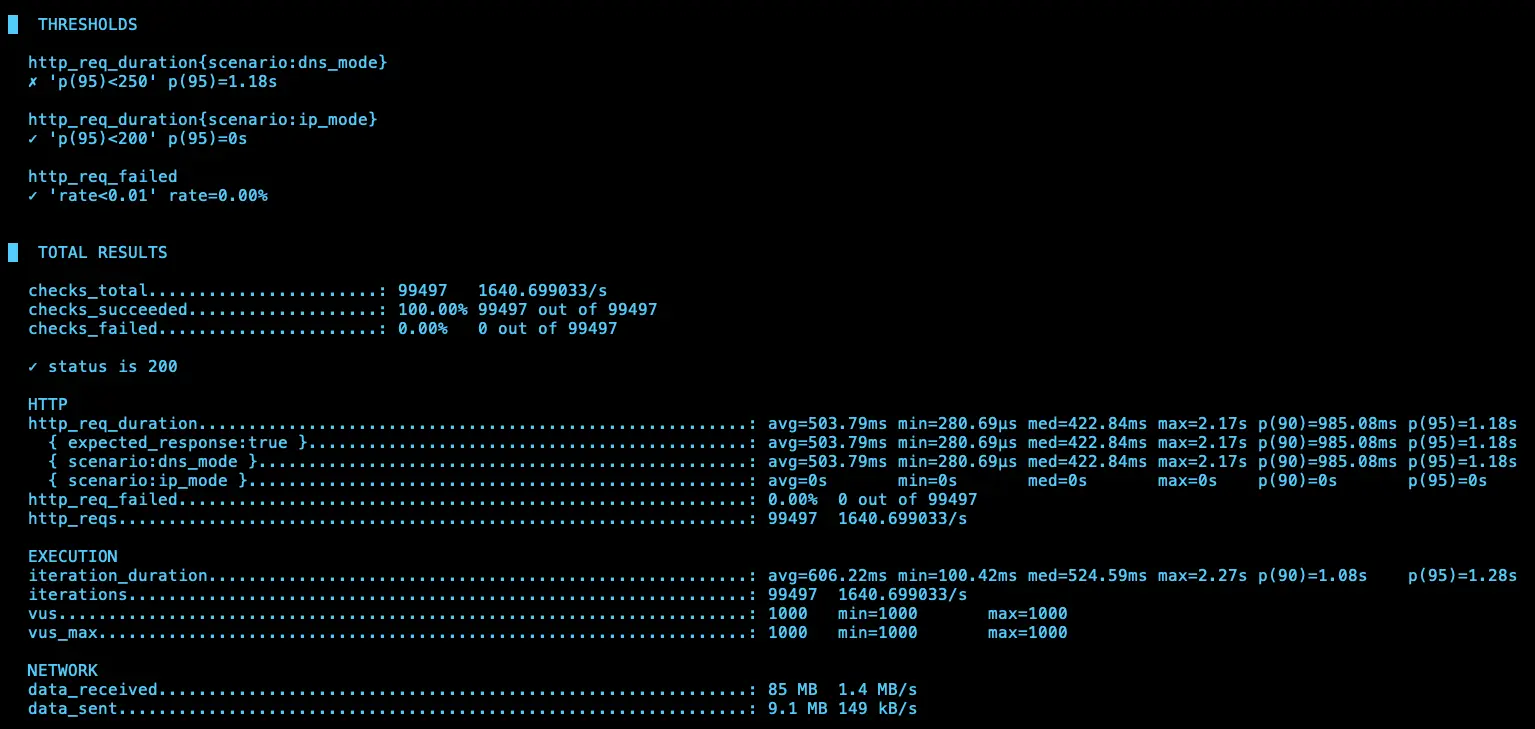
第三次測試
IP (avg=128.9ms / 4310 RPS)、DNS (avg=129.23ms / 4310 RPS)
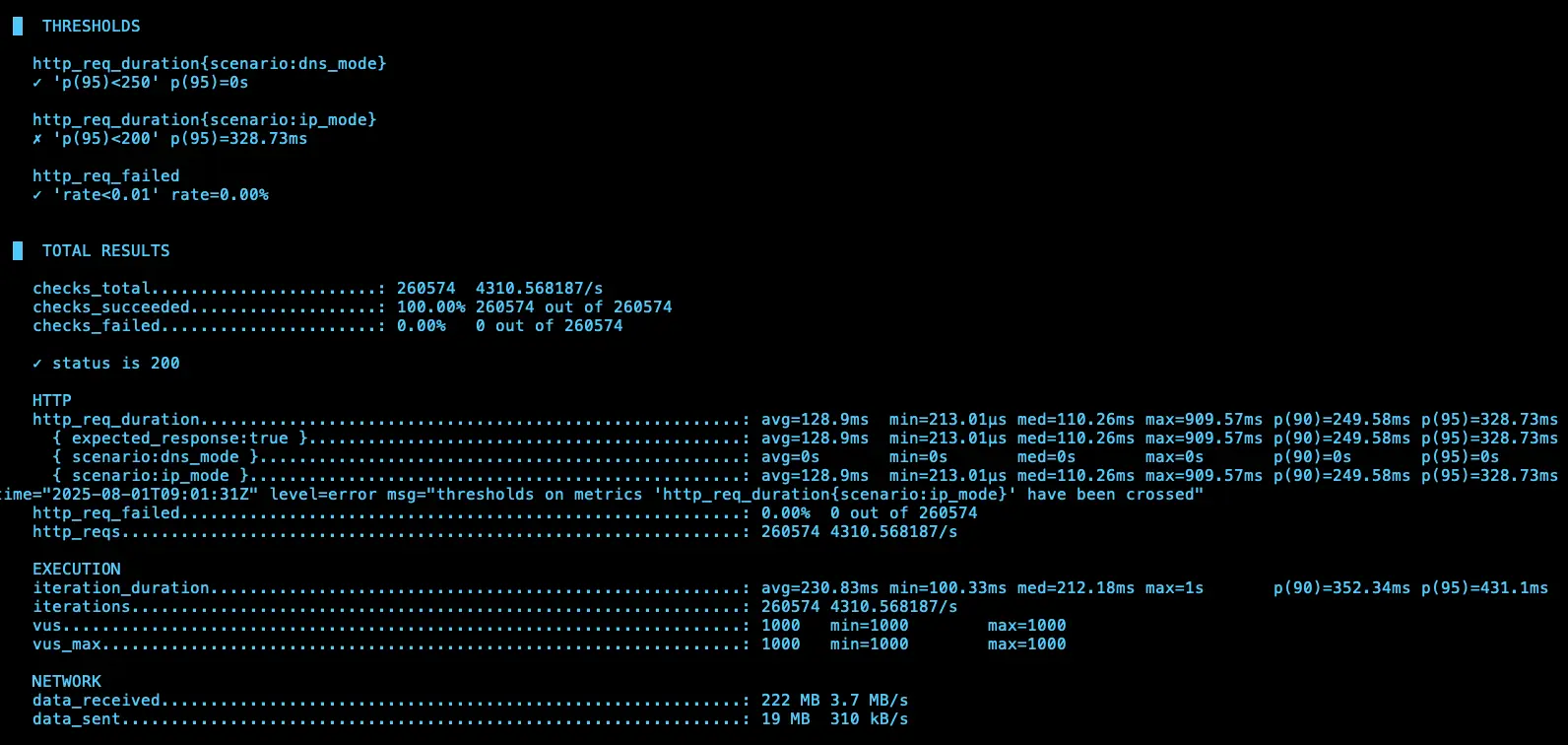
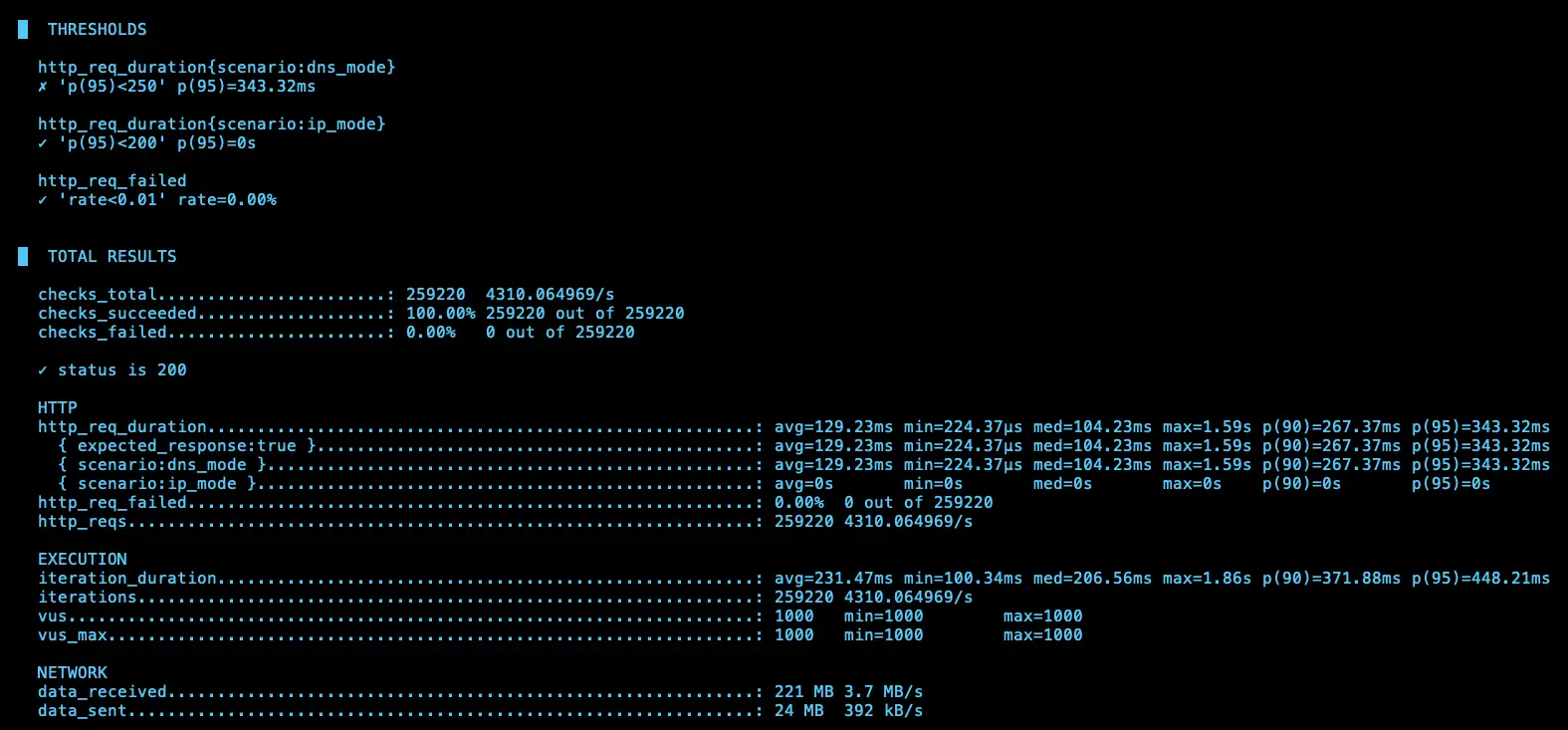
第四次測試
IP (avg=149.5ms / 3965 RPS)、DNS (avg=133.73ms / 4230 RPS)
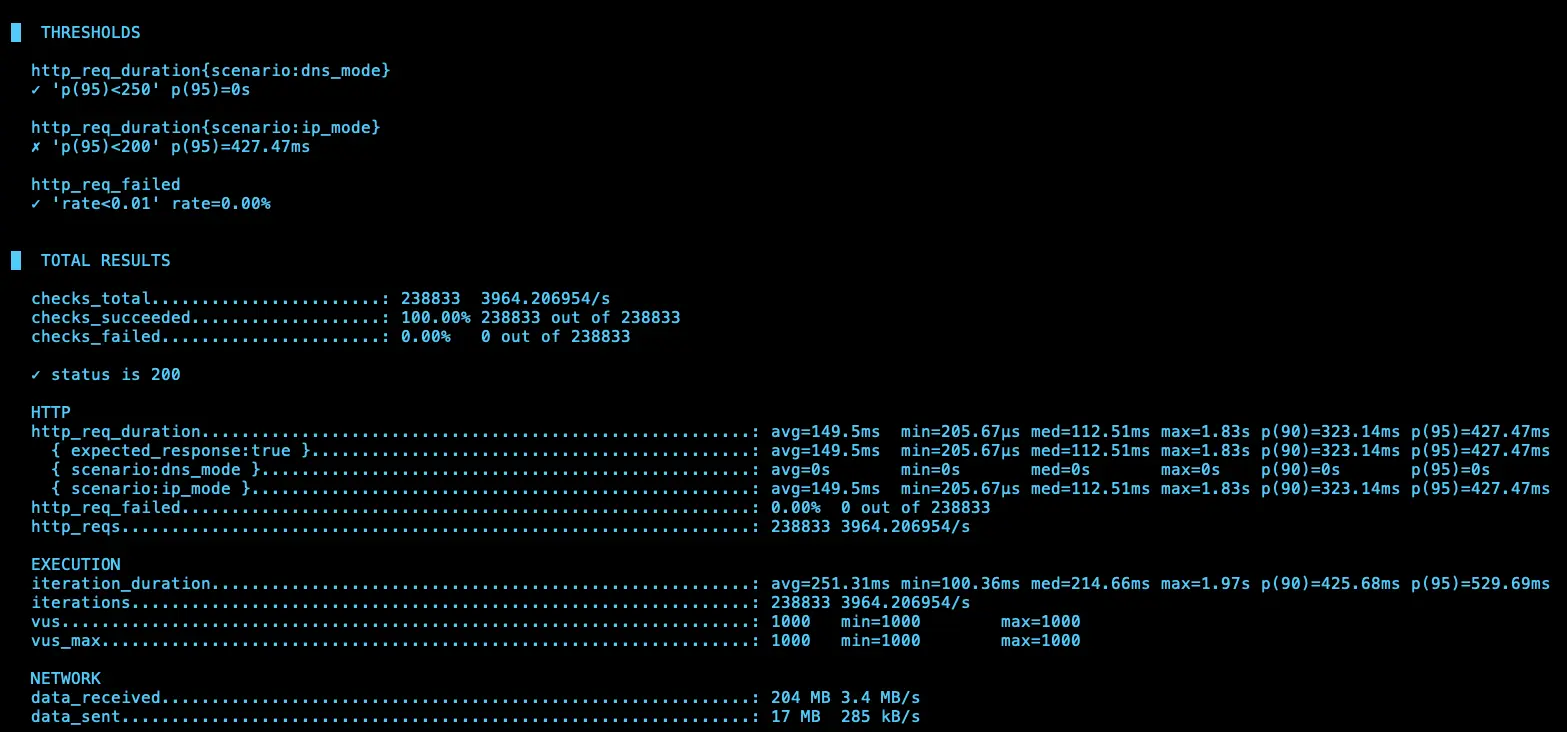
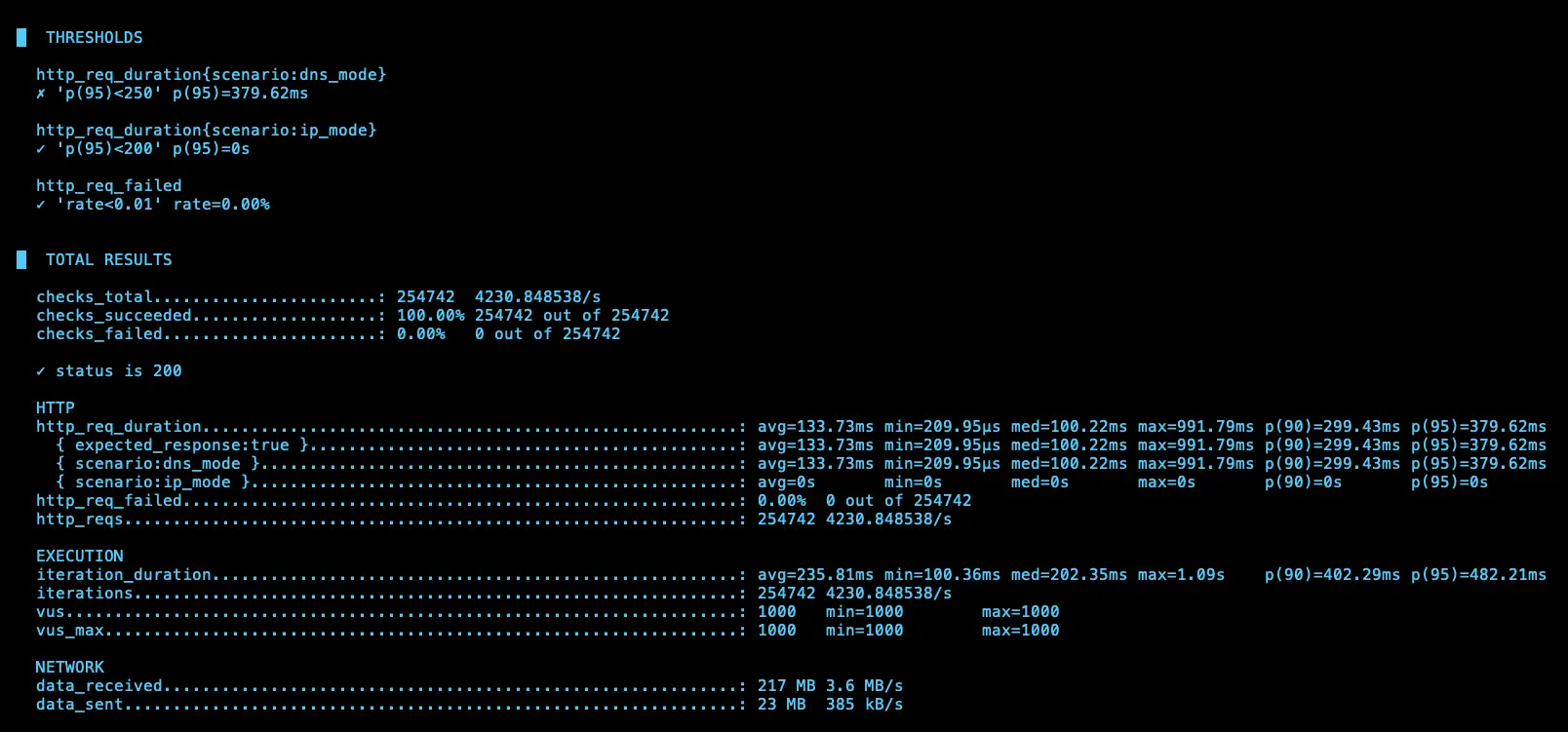
結論
理論上 ip 應該會比 dns 還要快,但測試 4 次發現其實不一定
結論
可以發現,使用 KubeDNS + NodeLocal DNSCache 的模式下,對於 KubeDNS 的依賴性降低了很多,因為 NodeLocal DNSCache 會先做 cache hit,這樣就算 KubeDNS 異常(只有 cluster 內的,且 cache 失效才會影響),否則不會影響到 pod 的 DNS 解析。
](/gcp/gke-kubedns-nodelocaldnscache/nodelocal-dns-cache-diagram.webp)
https://cloud.google.com/kubernetes-engine/docs/how-to/nodelocal-dns-cache?hl=zh-tw#architecture
由於官方流程圖有些細節沒有揭露的完成,我們有額外詢問 Google TAM,並畫出以下流程圖,Google TAM 也確認流程正確
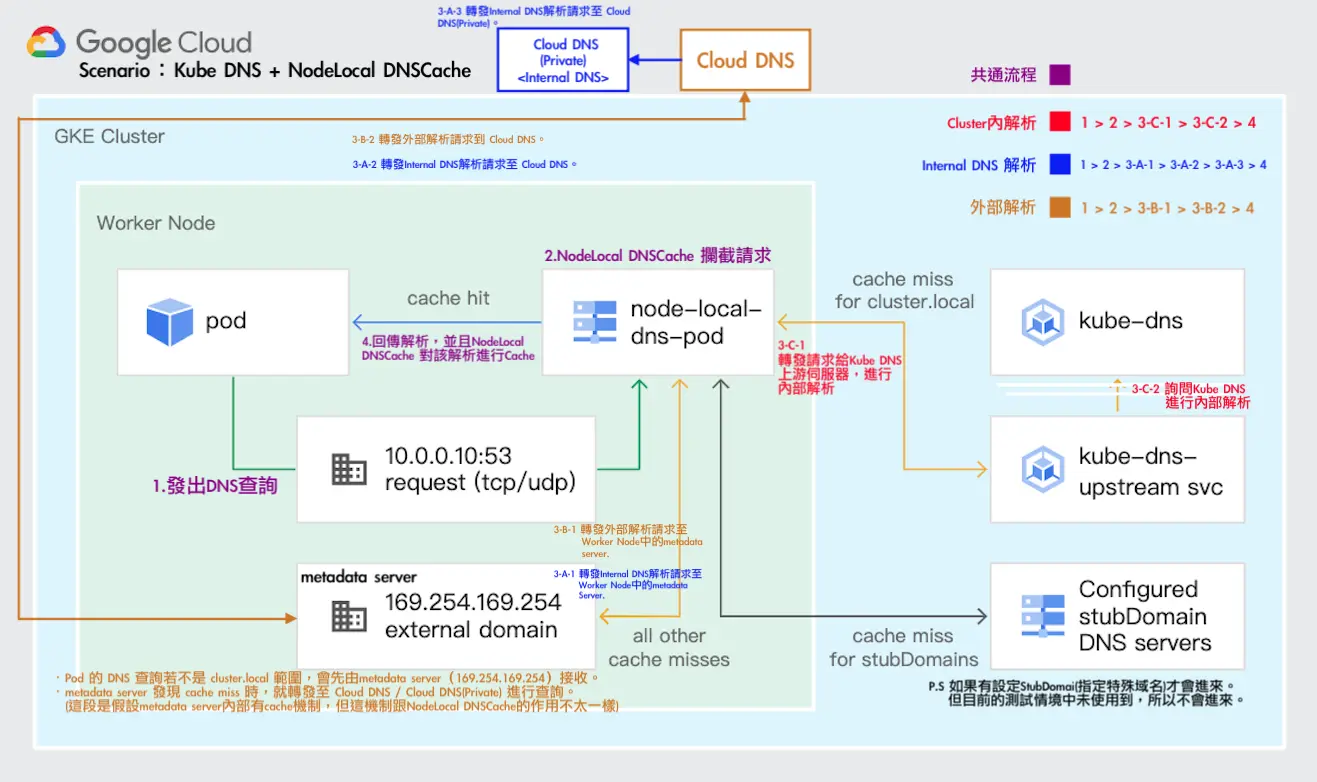
以下是我們與 Google 討論的內容:
我們:
MetaData Server 是否會快取外部DNS的解析結果?若會的話,是否 DNS Provider 改為 Cloud DNS才會有這個行爲發生?
公用的 Cloud DNS 是否有什麼統一的稱呼 (例:Common Cloud DNS…之類的)?或者就真的只叫 “Cloud DNS”?
Google:
會快取並遵循 TTL,無論是否設定為 Cloud DNS,內外部的 DNS 解析都需要透過 Cloud DNS 查詢,只有是否先經過 kube-dns 的差異,因此快取無論開啟 Cloud DNS 都會有
就叫 Cloud DNS,或內部稱 GCE DNS
這是 K8s 官方的 NodeLocalDNS 流程圖:
](/gcp/gke-kubedns-nodelocaldnscache/nodelocaldns.webp)
https://kubernetes.io/docs/tasks/administer-cluster/nodelocaldns/#architecture-diagram
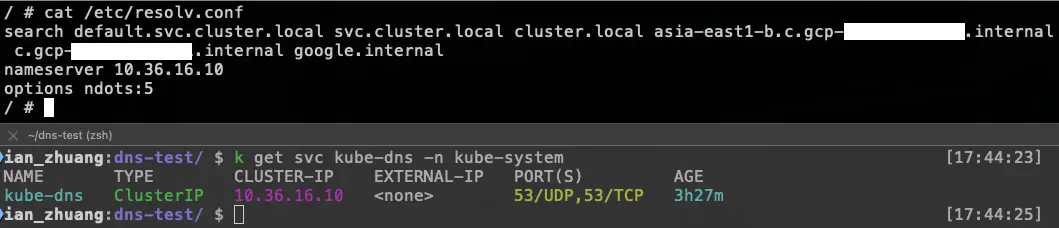
另外也可以從官方文件中得知 KubeDNS + NodeLocal DNSCache 的 /etc/resolv.conf 設定值,可以知道 Pod 最開始使用的 DNS 解析 Server 是誰。
](/gcp/gke-kubedns-nodelocaldnscache/resolv.webp)
參考資料
設定 NodeLocal DNSCache:https://cloud.google.com/kubernetes-engine/docs/how-to/nodelocal-dns-cache?hl=zh-tw