Kubernetes (K8s) 搭配 EFK 實作 (Deployment、StatefulSet、DaemonSet)
這是我們 Kubernetes 文章的第三篇,此文章會紀錄我將 EFK 建在 Kubernetes 上面,最後也會統整實作過程中,可能會遇到的一些問題,讓大家在學習時,可以更有效率,不用 debug 到死 😎😎
那由於本文會直接帶入程式,觀念部分,可以先查看:
- Kubernetes : Kubernetes (K8s) 介紹 - 基本
- kubernetes : Kubernetes (K8s) 介紹 - 進階 (Service、Ingress、StatefulSet、Deployment、ReplicaSet、ConfigMap)
- EFK : 用 EFK 收集容器日誌 (HAProxy、Redis Sentinel、Docker-compose)
此文章程式碼也會同步到 Github ,需要的也可以去查看歐!要記得先確定一下自己的版本 Github 程式碼連結 😆
版本資訊
- macOS:11.6
- Minikube:v1.25.2
- hyperkit:0.20200908
- Kubectl:Client Version:v1.22.5、Server Version:v1.23.3
- Elasticsearch:8.1.3
- Fluentd:v1.14.6-debian-elasticsearch7-1.0
- Kibana:8.1.3
實作
創建命名空間
在我們開始之前,我們首先建立一個命名空間,我們會將 EFK 所有的工具都安裝在此。那我想創建一個名為 kube-logging 的 namespace,先查詢現有的命名空間是否有重複:
$ kubectl get namespaces我們可以看到這些已經存在的 namespace :
NAME STATUS AGE
default Active 92m
kube-logging Active 89m
kube-node-lease Active 92m
kube-public Active 92m
kube-system Active 92m
kubernetes-dashboard Active 92m那要怎麼創建一個命名空間呢?先打開編輯器編輯名為 kube-logging.yaml:
apiVersion: v1
kind: Namespace
metadata:
name: kube-logging完成後,使用 apply 來創建命名空間:
$ kubectl apply -f kube-logging.yaml
namespace/kube-logging created再使用 kubectl get namespaces 查看是否多了一個名為 kube-logging 的命名空間:
$ kubectl get namespaces
NAME STATUS AGE
default Active 2m23s
kube-logging Active 88s
kube-node-lease Active 2m24s
kube-public Active 2m24s
kube-system Active 2m24s
kubernetes-dashboard Active 2m19s創建 Elasticsearch StatefulSet
我們已經創建好一個命名空間來放我們的 EFK,首先先部署副本數有 3 個的 Elasticsearch Pod。為什麼要使用 3 個 呢?使用 3 個 Elasticsearch Pod 是為了避免在高可用性、多節點叢集時出現錯誤,當其中一個 Elasticsearch Pod 故障,其他 2 個就會選舉後來接替,保證叢集可以繼續運行。
創建 Headless Service
我們先創建名為 elasticsearch_svc.yaml 的 yaml 檔,用來處理 service 的問題:
apiVersion: v1
kind: Service
metadata:
name: elasticsearch
namespace: kube-logging
labels:
app: elasticsearch
spec:
selector:
app: elasticsearch
clusterIP: None
ports:
- port: 9200
name: rest
- port: 9300
name: inter-node我們有創建一個命名空間,所以要先在 metadata 加入 namespace: kube-logging。記得要設定標籤,當我們將 Elasticsearch StatefulSet 與此 Service 關聯時,Service 會返回指向的帶有標籤的 Elasticsearch Pod。然後我們設置 clusterIP: None 定義該 Service 為 Headless Service。最後定義 Port 9200 為 REST API、Port 9300 為 Node 之間的通信。
一樣使用 apply 來建立 Service:
$ kubectl apply -f elasticsearch-svc.yaml
service/elasticsearch created我們這次直接查看 minikube dashboard:

創建 StatefulSet
創建名為 elasticsearch_statefulset.yaml 的 yaml 檔案 (因為程式長度,所以分開說明,要完整請參考 Github 程式碼連結):
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: es-cluster
namespace: kube-logging
spec:
serviceName: elasticsearch
replicas: 3
selector:
matchLabels:
app: elasticsearch
template:
metadata:
labels:
app: elasticsearch名稱取名為 es-cluster ,我一樣使用 kube-logging 的 namespace,設定 ServiceName elasticsearch 是確保 StatefulSet 中的每一個 Pod 都可以使用以下 DNS 位址進行訪問:es-cluster-[0,1,2].elasticsearch.kube-logging.svc.cluster.local ,其中 [0,1,2] 對應 Pod 分配的整數序號。
我們指定副本數為 3,並將 matchLabels 選擇器設定 app: elasticseach,我們在將其鏡像到該 .spec.template.metadata,.spec.selector.matchLabels 跟 .spec.template.metadata.labels 必須相同。
接續…
spec:
containers:
- name: elasticsearch
image: elasticsearch:8.1.3
resources:
limits:
cpu: 1000m
requests:
cpu: 100m
ports:
- containerPort: 9200
name: rest
protocol: TCP
- containerPort: 9300
name: inter-node
protocol: TCP
volumeMounts:
- name: data
mountPath: /usr/share/elasticsearch/data
env:
- name: cluster.name
value: k8s-logs
- name: node.name
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: discovery.seed_hosts
value: "es-cluster-0.elasticsearch,es-cluster-1.elasticsearch,es-cluster-2.elasticsearch"
- name: cluster.initial_master_nodes
value: "es-cluster-0,es-cluster-1,es-cluster-2"
- name: ES_JAVA_OPTS
value: "-Xms512m -Xmx512m"
- name: xpack.security.enabled # 記得要加上,因爲 Elasticsearch 8.x版本後會自動開啟SSL,如果沒有設定他就會一直重新啟動
value: "false"我們定義容器名稱是 elasticsearch,映像檔是 elasticsearch:8.1.3 ,要記得這個版本要與後面的 kibana 相同,我們在 resources 設置容器至少需要 0.1 CPU,最多可以到 1 個 CPU。一樣設定 Port 9200 為 REST API、Port 9300 為 Node 之間的通信,並將名為 data 的PersistentVolume 的容器掛載到容器的 /usr/share/elasticsearch/data。
最後幫容器設置一些環境變數:
cluster.name:Elasticsearch 叢集的名稱,我們設定為k8s-logs。node.name:節點名稱,我們設置 valueFrom 使用.metadata.name,它會解析為es-cluster-[0,1,2],取決節點的指定順序。discovery.seed_hosts:設置叢集中主節點列表,這些節點將會為節點發現過程中提供 Pod,但由於我們配置的 Headless Service,所以我們的 Pod 具有es-cluster-[0,1,2].elasticsearch.kube-logging.svc.cluster.localKubernetes DNS 解析。cluster.initial_master_nodes:這邊指定將參與主節點的選舉過程節點列表,這邊是通過節點node.name來辨識,不是透過主機名。ES_JAVA_OPTS:這邊我們設置-Xms512m -Xmx512m,告訴 JVM 使用最大跟最小 512 MB,可以依據資源來做調配。xpack.security.enabled:這是也是我在 elasticsearch 卡很久的一個設定,詳細的會在最後的常見問題中提到,大家只要記得 elasticsearch 8.x 以後都需要多這個。
接續…
initContainers:
- name: fix-permissions
image: busybox
command:
["sh", "-c", "chown -R 1000:1000 /usr/share/elasticsearch/data"]
securityContext:
privileged: true
volumeMounts:
- name: data
mountPath: /usr/share/elasticsearch/data
- name: increase-vm-max-map
image: busybox
command: ["sysctl", "-w", "vm.max_map_count=262144"]
securityContext:
privileged: true
- name: increase-fd-ulimit
image: busybox
command: ["sh", "-c", "ulimit -n 65536"]
securityContext:
privileged: true我們這個區塊定義了主容器運行前的初始化設定:
fix-permissions:因為默認情況下,Kubernetes 會將數據目錄掛載為root,導致 Elasticsearch 無法訪問,所以才會多這個運行chown將 Elasticsearch 數據目錄的所有者和組更改為1000:1000 /usr/share/elasticsearch/data。詳細可以參考 Notes for Production Use and Defaults。increase-vm-max-map:這邊是因為默認情況下內存會太低,所以多這個用sysctl -w來調整內存大小。詳細可以參考 Elasticsearch documentation。iincrease-fd-ulimit:它運行ulimit調整打開文件描述的最大數量。詳細可以參考 Notes for Production Use and Defaults。
接續…
volumeClaimTemplates:
- metadata:
name: data
labels:
app: elasticsearch
spec:
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 3Gi這邊定義了 StatefulSet 的 volumeClaimTemplates。Kubernetes 會幫 Pod 創建 PersistentVolume,我們在上面的命名將它取為 data,並與 app: elasticsearch StatefulSet 相同標籤。
我們將訪問的模式設定為 ReadWriteOnce,代表我們只能被單個節點以讀寫方式掛載,最後我們設定每個 PersistentVolume 的大小為 3GiB。
都完成後,我們一樣用 apply 部署 StatefulSet:
$ kubectl apply -f elasticsearch-statefulset.yaml
statefulset.apps/es-cluster created我們可以查看 minikube dashboard:
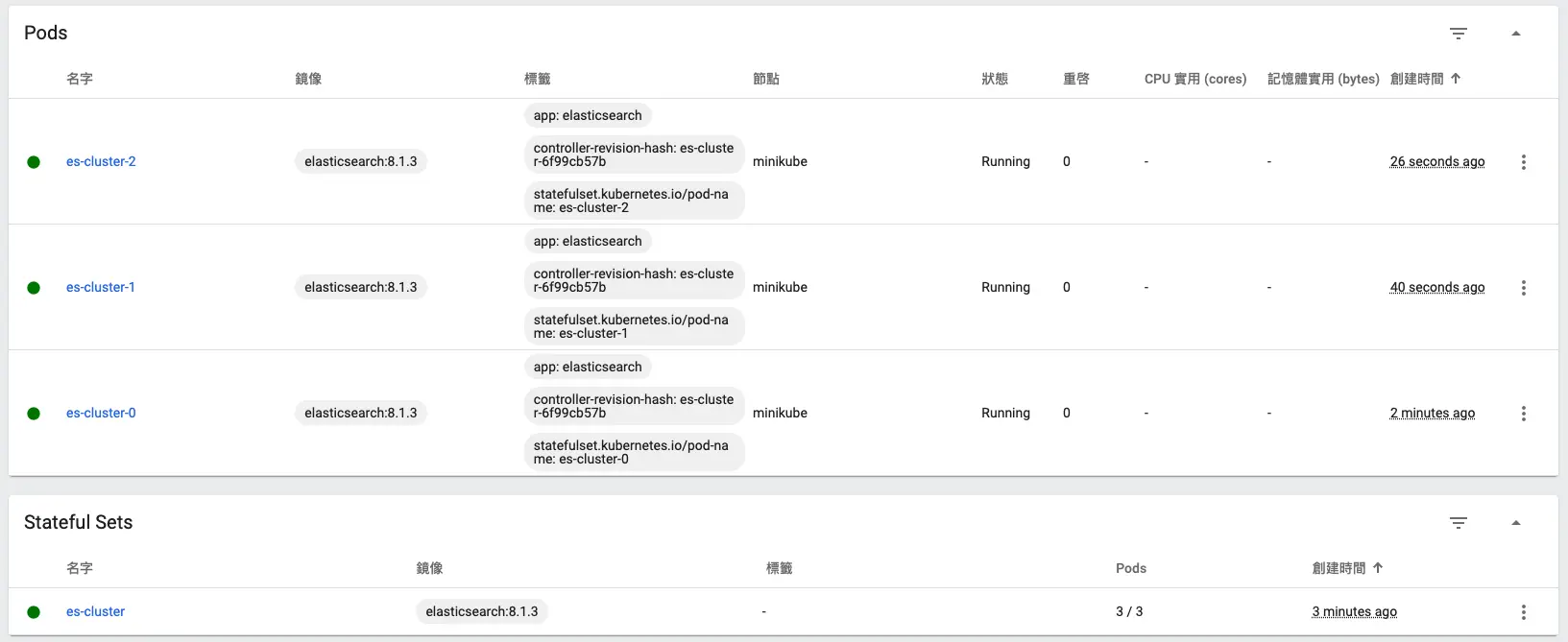
可以看到已經成功建好,接著我們使用 port-forward 來測試是否正常運作:
$ kubectl port-forward es-cluster-0 9200:9200 --namespace=kube-logging
$ curl http://localhost:9200/
{
"name" : "es-cluster-0",
"cluster_name" : "k8s-logs",
"cluster_uuid" : "aGxBystkQFW-xvjJ98Pxcw",
"version" : {
"number" : "8.1.3",
"build_flavor" : "default",
"build_type" : "docker",
"build_hash" : "39afaa3c0fe7db4869a161985e240bd7182d7a07",
"build_date" : "2022-04-19T08:13:25.444693396Z",
"build_snapshot" : false,
"lucene_version" : "9.0.0",
"minimum_wire_compatibility_version" : "7.17.0",
"minimum_index_compatibility_version" : "7.0.0"
},
"tagline" : "You Know, for Search"
}如果像我上面一樣有跳出 ”You Know, for Search“ 就代表 Elasticsearch 已經在正常運作囉 🥳
創建 Kibana Deployment Service
要在 Kubernetes 上啟動 Kibana,我們要先創建一個名為 Service kibana,以及包含一個副本的 Deployment。我們先創建名為 kibana.yaml 的 yaml 檔:
apiVersion: v1
kind: Service
metadata:
name: kibana
namespace: kube-logging
labels:
app: kibana
spec:
ports:
- port: 5601
selector:
app: kibana
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: kibana
namespace: kube-logging
labels:
app: kibana
spec:
replicas: 1
selector:
matchLabels:
app: kibana
template:
metadata:
labels:
app: kibana
spec:
containers:
- name: kibana
image: kibana:8.1.3
resources:
limits:
cpu: 1000m
requests:
cpu: 100m
env:
- name: ELASTICSEARCH_URL
value: http://elasticsearch:9200
ports:
- containerPort: 5601一樣我們要把 kibana 加入 kube-logging 的命名空間,讓它以去調用其他服務,並賦予 app: kibana 標籤。並指定本機訪問 Port 為 5601,並使用 app: kibana 標籤來選擇服務的 Pod。我們在 Deployment 定義 1 個 Pod 副本,我們使用 kibana:8.1.3 image,記得要跟 Elasticsearch 使用相同版本,此外我們還有設定 Pod 最少使用 0.1 個 CPU、最多使用 1 個 CPU。最後在環境變數中使用 ELASTICSEARCH_URL 設定 Elasticsearch 的叢集以及 Port。
都完成後,我們來開始部署:
$ kubectl apply -f kibana.yaml
service/kibana created
deployment.apps/kibana created一樣我們用 minikube dashboard 來查看是否部署成功:
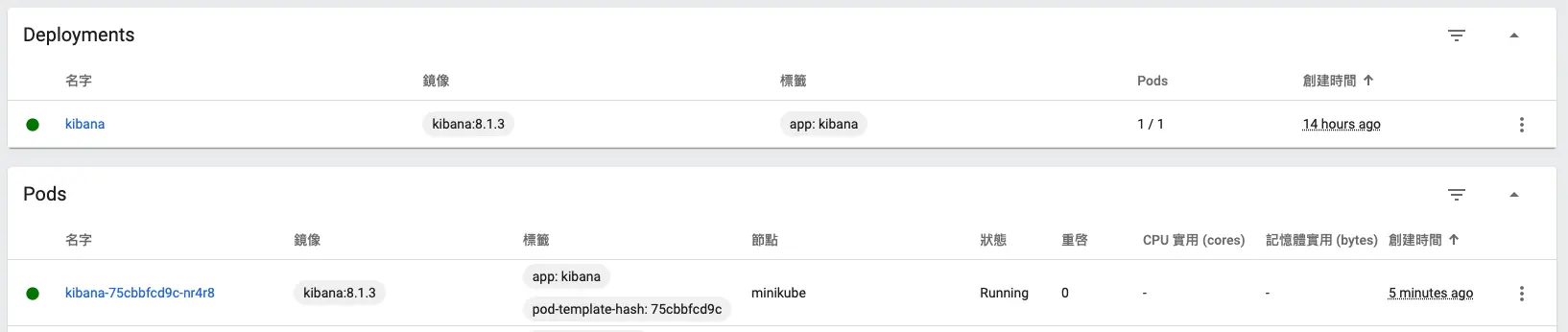
沒有問題後,我們用 port-forward 將本地 Port 轉發到 Pod 上:
$ kubectl port-forward kibana-75cbbfcd9c-nr4r8 5601:5601 --namespace=kube-logging
Forwarding from 127.0.0.1:5601 -> 5601
Forwarding from [::1]:5601 -> 5601
Handling connection for 5601開啟瀏覽器瀏覽 http://localhost:5601,如果可以進入 Kibana,就代表成功將 Kibana 部署到 Kubernetes 叢集中:
創建 Fluentd DaemonSet
我們要將 Fluentd 設置成 DaemonSet,讓它在 Kubernetes 叢集中每個節點上運行 Pod 副本。用 DaemonSet 控制器,可以將叢集中每個節點部署 Fluentd Pod,詳細可以參考 Using a node logging agent。在 Kubernetes 中,容器化的應用程式會透過 stdout 將日誌 log 定向到節點上的 JSON 文件。Fluentd Pod 會追蹤這些日誌文件、過濾日誌事件、轉換日誌的數據,並發送到我們部署的 Elasticsearch 後端。
除了容器的日誌,Fluentd 還會追蹤 Kubernetes 系統日誌,例如:kubelet、kube-proxy 和 Docker 日誌。
先創建一個 fluentd.yaml 的 yaml 檔 (因為程式長度,所以分開說明,要完整請參考 Github 程式碼連結):
創建 ServiceAccount
apiVersion: v1
kind: ServiceAccount
metadata:
name: fluentd
namespace: kube-logging
labels:
app: fluentd我們先創建一個服務帳號 fluentd,Fluentd Pod 將使用它來訪問 Kubernetes API。我們在 kube-logging namespace 中創建它並再次賦予它 label app: fluentd。
創建 ClusterRole
接著…
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: fluentd
labels:
app: fluentd
rules:
- apiGroups:
- ""
resources:
- pods
- namespaces
verbs:
- get
- list
- watch在這邊我們定義一個 ClusterRole fluentd,設定我們對叢集範圍的 Kubernetes 資源(如節點)的訪問權限,我們設定 get、list、watch 等權限。
創建 ClusterRoleBinding
接著…
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: fluentd
roleRef:
kind: ClusterRole
name: fluentd
apiGroup: rbac.authorization.k8s.io
subjects:
- kind: ServiceAccount
name: fluentd
namespace: kube-logging我們定義一個將 ClusterRole 綁定到 ServiceAccount 的 ClusterRoleBinding 調用。
創建 DaemonSet
接著…
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentd
namespace: kube-logging
labels:
app: fluentd定義一個可以在 kube-logging namespace 中調用的 DaemonSet,並給它一個 app: fluentd 標籤。
接著…
spec:
selector:
matchLabels:
app: fluentd
template:
metadata:
labels:
app: fluentd
spec:
serviceAccount: fluentd
serviceAccountName: fluentd
tolerations:
- key: node-role.kubernetes.io/master
effect: NoSchedule
containers:
- name: fluentd
image: fluent/fluentd-kubernetes-daemonset:v1.14.6-debian-elasticsearch7-1.0
env:
- name: FLUENT_ELASTICSEARCH_HOST
value: "elasticsearch.kube-logging.svc.cluster.local"
- name: FLUENT_ELASTICSEARCH_PORT
value: "9200"
- name: FLUENT_ELASTICSEARCH_SCHEME
value: "http"
- name: FLUENTD_SYSTEMD_CONF
value: disable我們先匹配 .metadata.labels 定義的標籤 app: fluentd ,然後為 DaemonSet 分配 fluentd Service Account。選擇 app: fluentd 作為這個 DaemonSet 管理的 Pod。
我們定義 NoSchedule 容忍度來匹配 Kubernetes master node 上的等效污點。他可以確保 DaemonSet 也被部署到 Kubernetes 主服務器。
接下來定義 Pod 容器,我們將名稱取為 fluentd,我們使用的映像檔是 fluent/fluentd-kubernetes-daemonset:v1.14.6-debian-elasticsearch7-1.0,最後配置一些環境變數:
FLUENT_ELASTICSEARCH_HOST:設置我們之前定義的 Elasticsearch Headless 位址。elasticsearch.kube-logging.svc.cluster.local會解析 3 個 Elasticsearch Pod 的 IP 地址列表。FLUENT_ELASTICSEARCH_PORT:設置我們之前定義的 Elasticsearch9200Port。FLUENT_ELASTICSEARCH_SCHEME:我們設置http。FLUENTD_SYSTEMD_CONF:我們將systemd在容器中設定相關的輸出設置為disable。
接著…
resources:
limits:
memory: 512Mi
requests:
cpu: 100m
memory: 200Mi
volumeMounts:
- name: varlog
mountPath: /var/log
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
readOnly: true
terminationGracePeriodSeconds: 30
volumes:
- name: varlog
hostPath:
path: /var/log
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers我們設置 Fluentd Pod 上使用 512 MiB 的內存限制,並保證 0.1 個 CPU 跟 200 MiB 的內存。我們將 varlog /var/log 以及 varlibdockercontainers var/lib/docker/containers 一併掛載進容器內。最後一個設定是 Fluentd 在收到信號 terminationGracePeriodSeconds 後有 30 秒的時間可以優雅的關閉。
都定義完成後,我們部署 Fluentd DaemonSet:
$ kubectl apply -f fluentd.yaml
serviceaccount/fluentd created
clusterrole.rbac.authorization.k8s.io/fluentd created
clusterrolebinding.rbac.authorization.k8s.io/fluentd created
daemonset.apps/fluentd created一樣我們用 minikube dashboard 來查看是否部署成功:
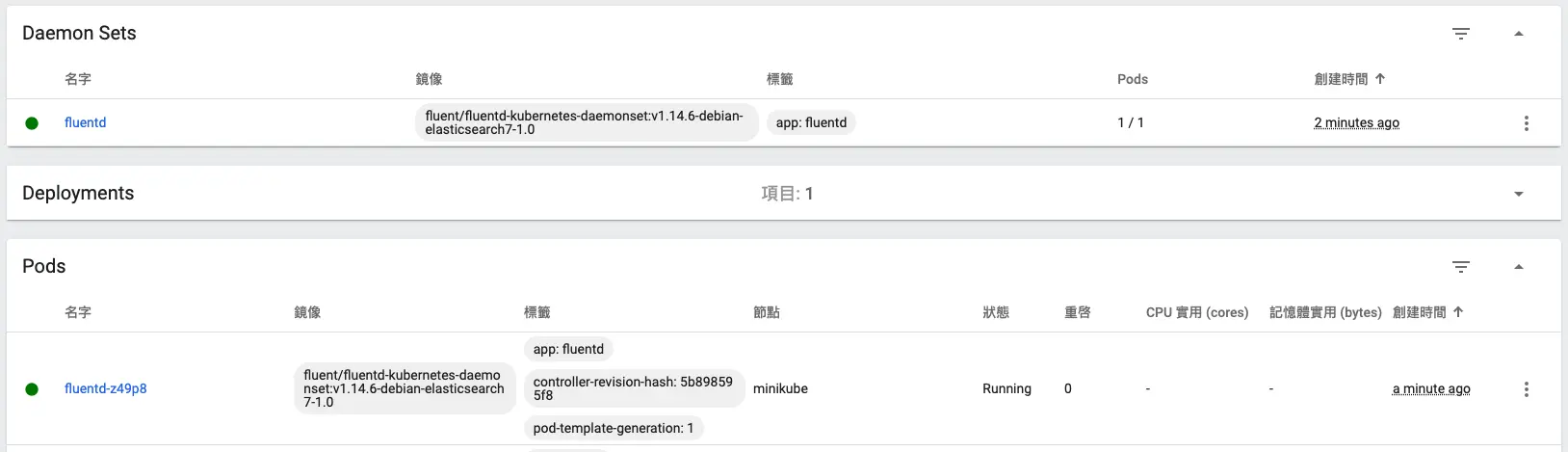
我們使用剛剛的 kibana port-forward 將本地 Port 轉發到 Pod 上:
$ kubectl port-forward kibana-75cbbfcd9c-nr4r8 5601:5601 --namespace=kube-logging
Forwarding from 127.0.0.1:5601 -> 5601
Forwarding from [::1]:5601 -> 5601
Handling connection for 5601開啟瀏覽器瀏覽 http://localhost:5601,點選 Management > Stack Management:
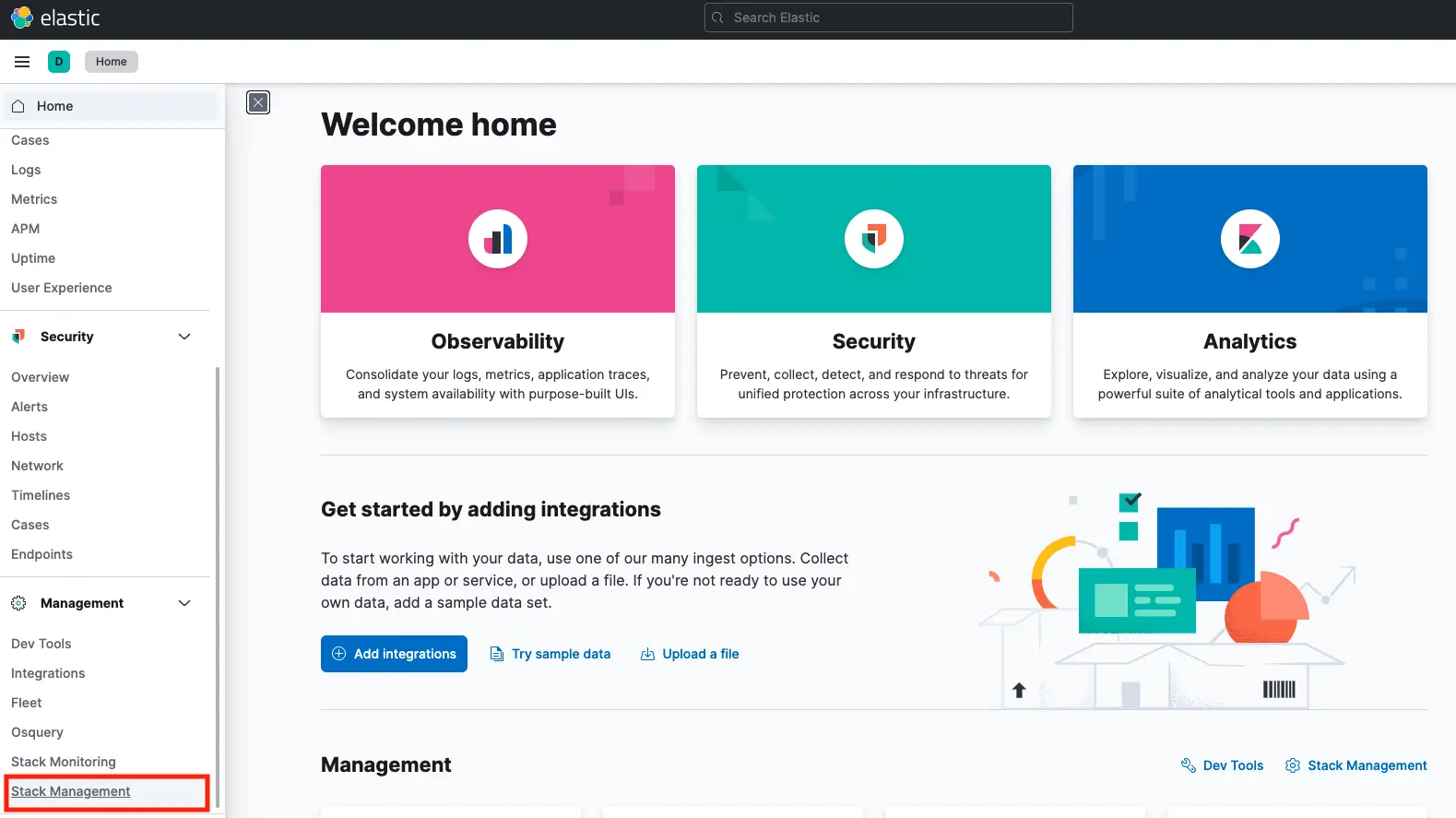
點選 Kibana > Data Views,會看到跳出一個視窗,有一個按鈕寫 Create data view:
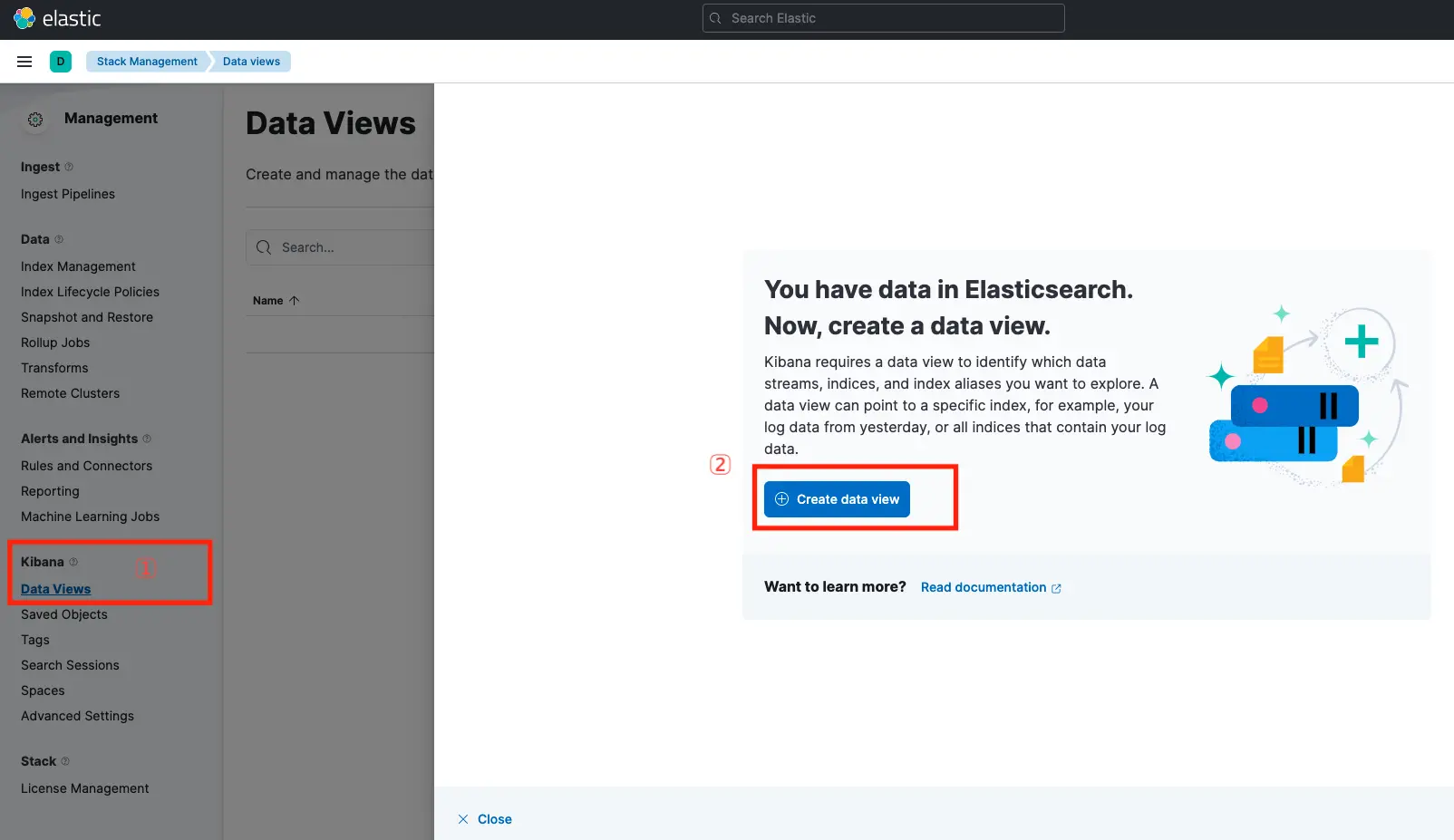
Name 輸入 logstash* ,並選擇 @timestamp 來用時間過濾日誌,最後按下 Create date view:
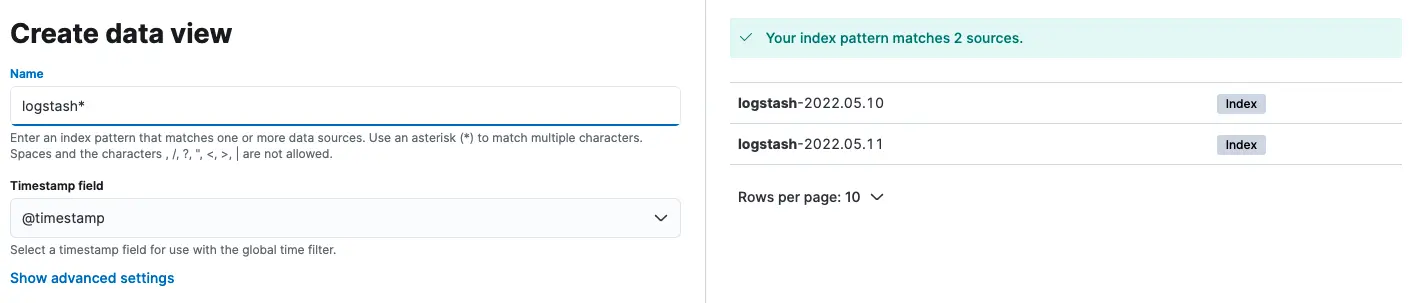
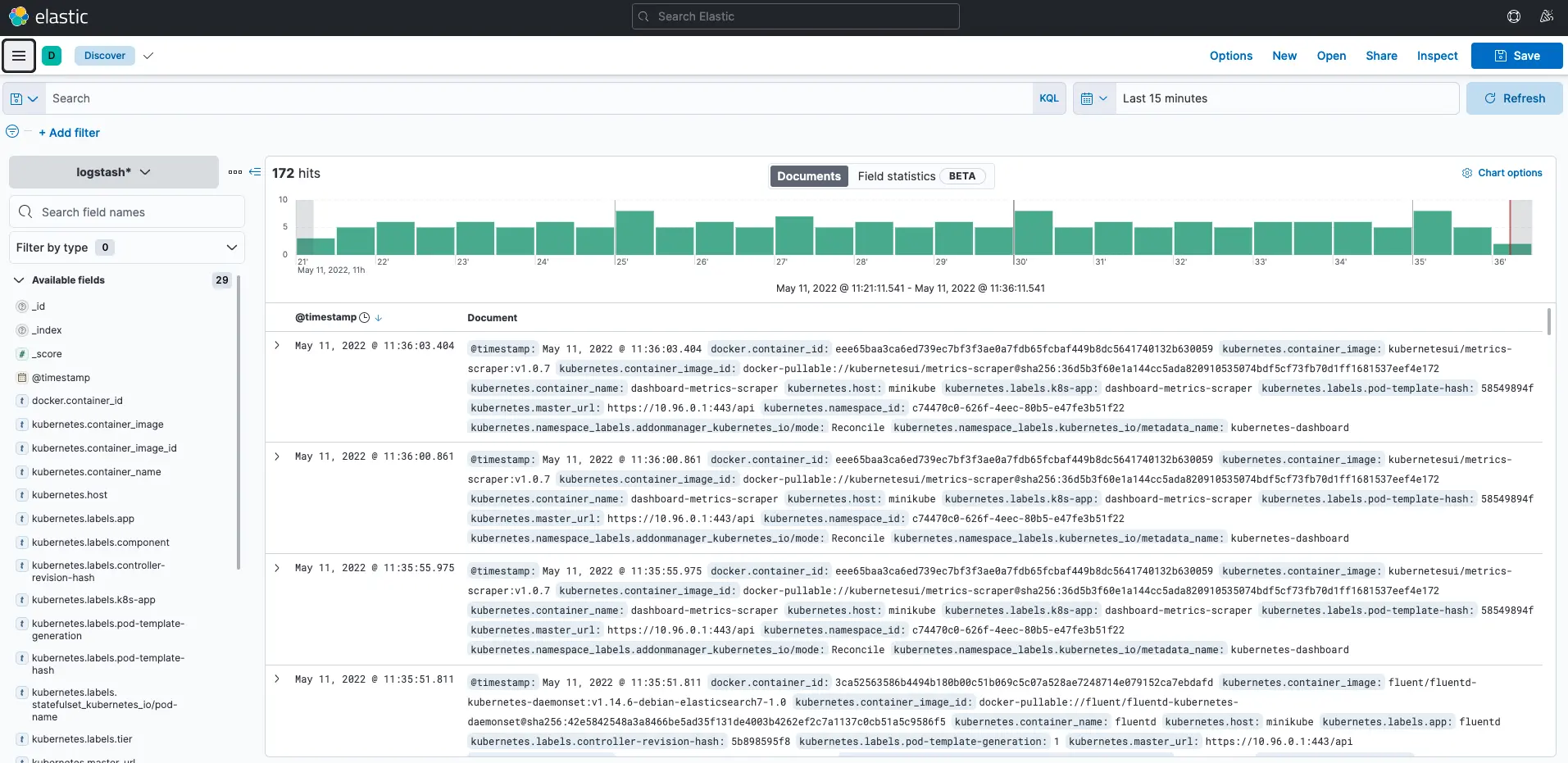
設定好 logstash* 的 Data views,再點選左邊欄位的 Discover:
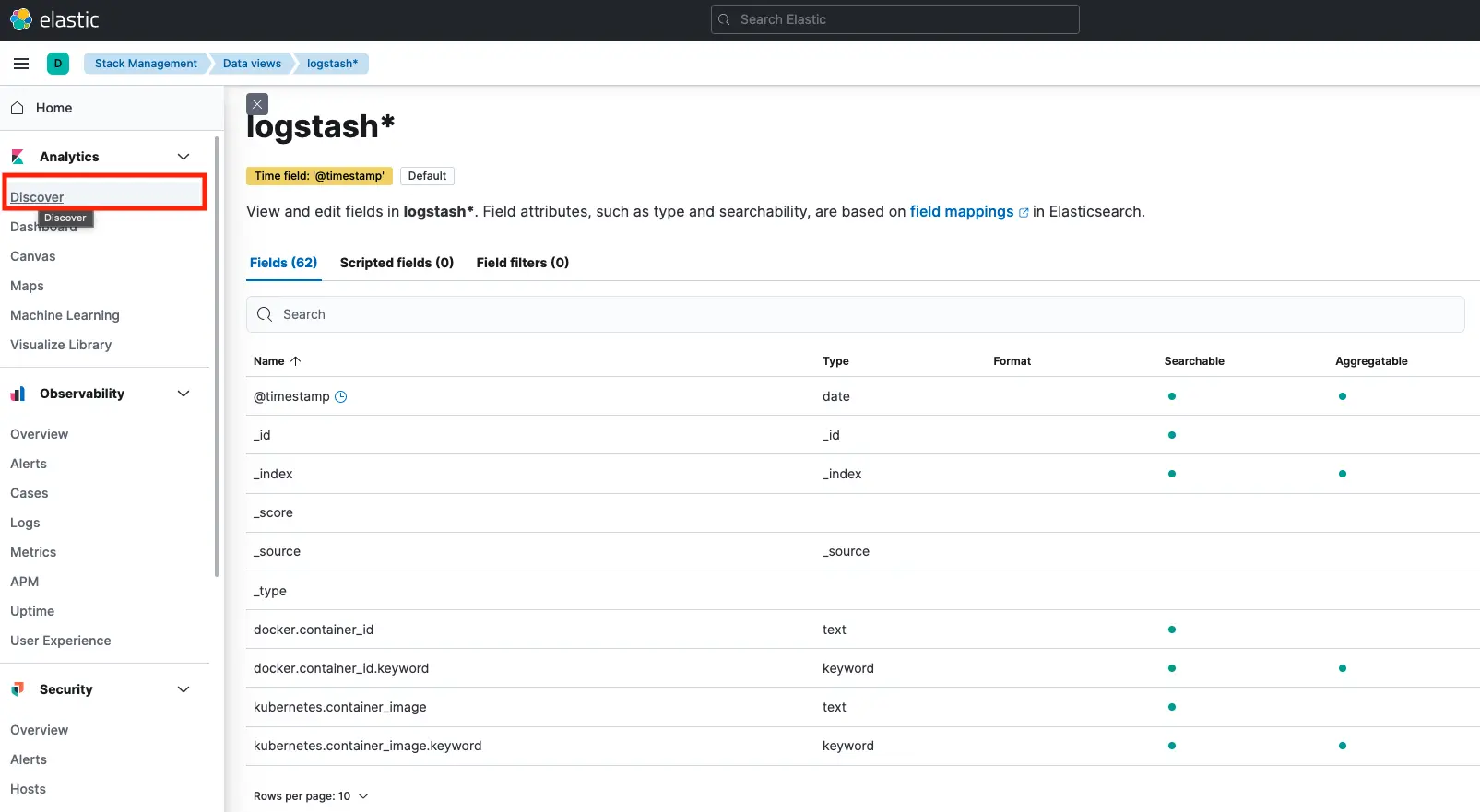
就可以看到顯示容器的 log 日誌拉!
部署常見問題及解決辦法
常見問題
Q:Elasticsearch 部署成功後會一直重新啟動?
Ans:原因是 Elasticsearch 從 8.x 版本後,會自動開啟 SSL 認證,我們在 env 環境變數設定時,如果沒有多加 SSL Key 等設定值,Elasticsearch 這個 Pod 會啟動後,一直重新啟動,導致服務無法正常使用,只需要在環境變數中加入 xpack.security.enabled ,設定為 false 就可以解決。
參考資料
How To Set Up an Elasticsearch, Fluentd and Kibana (EFK) Logging Stack on Kubernetes