Pod 出現 cURL error 6: Could not resolve host
此篇主要是來記錄一下在正式環境服務出現 cURL error 6: Could not resolve host 的問題,以及如何解決。
問題發生
當天 RD 在公窗反應說,API 程式去打其他單位或是 Google BigQuery 的 API 時,會出現 cURL error 6: Could not resolve host 的錯誤,但這個錯誤是偶發性錯誤,且出現錯誤的 Pod 也不是固定,也會出現在不同的 node 上。
當下檢查服務是正常的,也沒有任何異常,因此我們馬上開了 Google Support Ticket 來詢問。
解決辦法 & 後續規劃
自行測試
在等待 Google Support 回覆同時,也先在網路上搜尋出現 cURL error 6: Could not resolve host 的相關錯誤,主要都是因為 DNS 導致,因此我們也先檢查了一下目前 DNS 的設定。
參考了 Google 的 kube-dns 文件後 Setting up NodeLocal DNSCache/Scaling up kube-dns,我們嘗試調整 kube-dns-autoscaler configmap 的設定:
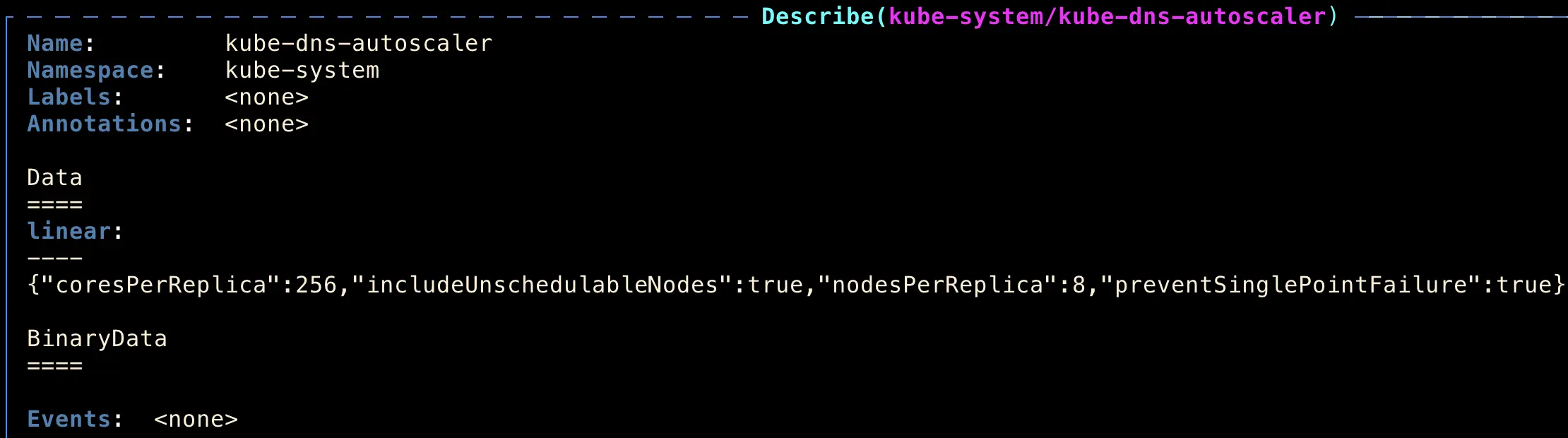
並觀察一陣子後發現,出現 cURL error 6: Could not resolve host 的錯誤 Log 已經沒有再出現,因此我們認為是 DNS 的問題,並回報給 Google Support。
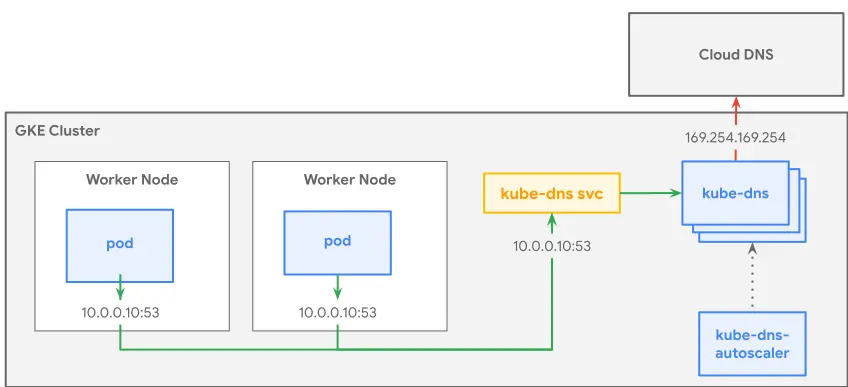
Kube-dns 的 Pod 是由 kube-dns-autoscaler 的 configmap 來控制 Pod 數量,如圖:
kube-dns-autoscaler configmap 設定
我們來說明一下這個設定內容是什麼 (下面會先以 GCP 的 kube-dns 官網文件來補充說明,而不是上面圖片):
linear: '{
"coresPerReplica": 256,
"includeUnschedulableNodes": true,
"nodesPerReplica": 16,
"min": 1,
"max": 5,
"preventSinglePointFailure": true
}'- coresPerReplica:多少個 cores 啟動一個 kube-dns pod (預設 256,也就是每 256 core 才會啟動一個 kube-dns pod)
- nodesPerReplica:多少個 node 啟動一個 kube-dns pod (預設 16,也就是每 16 node 才會啟動一個 kube-dns pod)
- min:最小 kube-dns pod 數量
- max:最大 kube-dns pod 數量
GCP kube-dns 官網文件建議:
- 要對
nodesPerReplica設定比較低的值,確保在叢集節點擴充時,kube-dns pod 數量也會跟著增加。 - 也強烈建議設定一個明確的 max 值,以確保 GKE control plane 不會因大量的 kube-dns pod 去使用 Kubernetes API 而過載。
kube-dns 計算方式
kube-dns 的 pod 數量計算方式如下:
replicas = max( ceil( cores × 1/coresPerReplica ) , ceil( nodes × 1/nodesPerReplica ), maxValue )情境一:假設我現在有 16 個 node,core 數量會是 50,那麼 kube-dns pod 數量就會是:
replicas = max( ceil(50 × 1/256) , ceil(16 × 1/16))
> replicas = max( 1 , 1)
> replicas = 1情境二:假設我現在有 32 個 node,core 數量會是 100,那麼 kube-dns pod 數量就會是:
replicas = max( ceil(100 × 1/256) , ceil(32 × 1/16))
> replicas = max( 1 , 2)
> replicas = 2情境三:假設我現在有 96 個 node,core 數量會是 300,有多設定 max 是 5,那麼 kube-dns pod 數量就會是:
replicas = max( ceil(300 × 1/256) , ceil(96 × 1/16))
> replicas = max( 2 , 6)
> replicas = 6但是我們有設定 max 是 5,所以最後 kube-dns pod 數量就會是 5,不會超過 5。
為了確保叢集 DNS 可用性的水平,也建議幫 kube-dns 設定 mix 值。
從上面計算方法也可以知道,當叢集具有多個核心的節點時,coresPerReplica 會佔主導地位。當叢集使用核心數較少的節點數,nodesPerReplica 佔主導地位。通常應該會以 nodesPerReplica 來設定。
調整完 kube-dns-autoscaler 的 configmap 設定,不需要重啟服務,kube-dns 就會自動 scale up or scale down pod 數
最後等待 Google Support 回覆,並告知已經調整 kube-dns-autoscaler configmap 的設定,並觀察一陣子後,問題已經解決。
Google Support 回覆
Google Support 回覆:
簡單解釋一下為什麼 scale up kube-dns pods 數量會有幫助:
當 Pod 做 DNS 查詢時,因為你們有啟用 NodeLocal DNSCache,所以他會先找 cache,如果沒有 cache 就會回 kube-dns 查詢。
我們在表象上先觀察到 NodeLocal DNSCache latency 很高,而這有兩個可能,一個當然可能是自身問題,但更大的可能性是當 cache 要回源跟 kube-dns 查找時,kube-dns 已經沒辦法再承接更多 request,所以 NodeLocal DNSCache 會一直嘗試 retry,我們在指標上也看到 latency 拉高並持平在一個水位顯示出某個瓶頸。
在經過 kube-dns 增加 pod 操作之後,看起來後續 DNS 查詢可以順利被處理跟 cache,所以問題就大幅緩解。
Google Support 建議
- 架構優化:未來可以評估用 CloudDNS 取代 kube-dns,CloudDNS 為託管服務,可以自動 scale up 來處理效能問題。參考文件
- 監控:如果短期暫時無法替換 CloudDNS,建議可在 kube-dns 安裝 agent 做監控,當接近效能瓶頸時,可以提前 scale up kube-dns pod。非官方參考文件
後續規劃
但由於我們公司最近也在考慮 multi-cloud 的方案,所以暫時不考慮用 GCP 雲供應商的 CloudDNS 取代 kube-dns,我們想研究看看另一套 coreDNS 是否能夠解決這個問題。
有興趣可以參考下一篇文章:Kube DNS vs Core DNS。
參考資料
k8s dns 故障 Pod 无法解析主机名 Couldn‘t resolve host:https://blog.csdn.net/hknaruto/article/details/109361342
Setting up NodeLocal DNSCache/Scaling up kube-dns:https://cloud.google.com/kubernetes-engine/docs/how-to/nodelocal-dns-cache#scaling_up_kube-dns
DNS on GKE: Everything you need to know:https://medium.com/google-cloud/dns-on-gke-everything-you-need-to-know-b961303f9153
Monitoring kube-dns pods in GKE:https://medium.com/@prageeshag/monitoring-kube-dns-pods-in-gke-83b76a0ef3d9